
¶ Where does, or might, your streaming money go? · 13 July 2025 listen/tech
There's a whole chapter in my book about how royalty distribution from streaming music services works, and when I worked at Spotify I could run the entire service's actual usage through potential alternate distribution models to see how they would affect artists differently. You can't do that, and I can't anymore either.
But if you've requested your own streaming history from Spotify, and loaded it into Curio, you can at least explore how alternate distribution models might distribute your money to the artists † ‡ you love.
You can start with this query comparing the usual pro-rata scheme to one that distibutes each listener's money according to their individual listening-time per artist.
Here's the query:
To do this without access to proprietary business data, we have to make a couple legally-arbitrary assumptions about two key internal Spotify numbers.
One is the fraction of Spotify revenue, for your subscription country and type, that gets paid out to licensors. This is variously quoted as "more than two-thirds" or "about 70%" in the press, and the exact number depends in a complicated way on local statutory rates, licensor deals and even sometimes the complicity of specific labels or artists in Spotify's grim attempts to fractionally improve their own margins. You can make up your own mind about what you want to believe this number to be, and if your mind makes up some number other than 0.7, you should replace the 0.7 in the ??rates= line with your alternative.
The second number is the average number of plays (industry-defined as "you listened to at least :30 of a song, but it doesn't make any difference how much if it's at least that much") for your subscription country and type. One common public guess at this average across all Spotify listeners is 500 plays/month; total Spotify membership is weighted about 3:2 in favor of ad-subsidized "free" listeners over subscribers; Daniel Ek once said in public that premium listeners spend about 3x as much time listening as free listeners, on average. Putting these numbers together with math (not shown here) suggests a premium-user average somewhere around 800. If you don't like that 800, replace the 800 in that same line with whatever you like better.
The 10.99 in my example is the current monthly cost of a US Basic account, which I choose (in both the moral and exemplary senses) because Spotify is engaged in a disingenuous ongoing effort to define the nominal Premium account as a supposedly-equal-value bundle of music and audiobooks so that they don't have to pay as much in music-publishing royalties. In this particular example I have filtered my listening history to data from calendar 2024, and thus have multiplied the monthly subscription and stream-count numbers both by 12. You could also take both 12s out and filter to any single month.
Using these numbers, here's what I get for my own 2024:
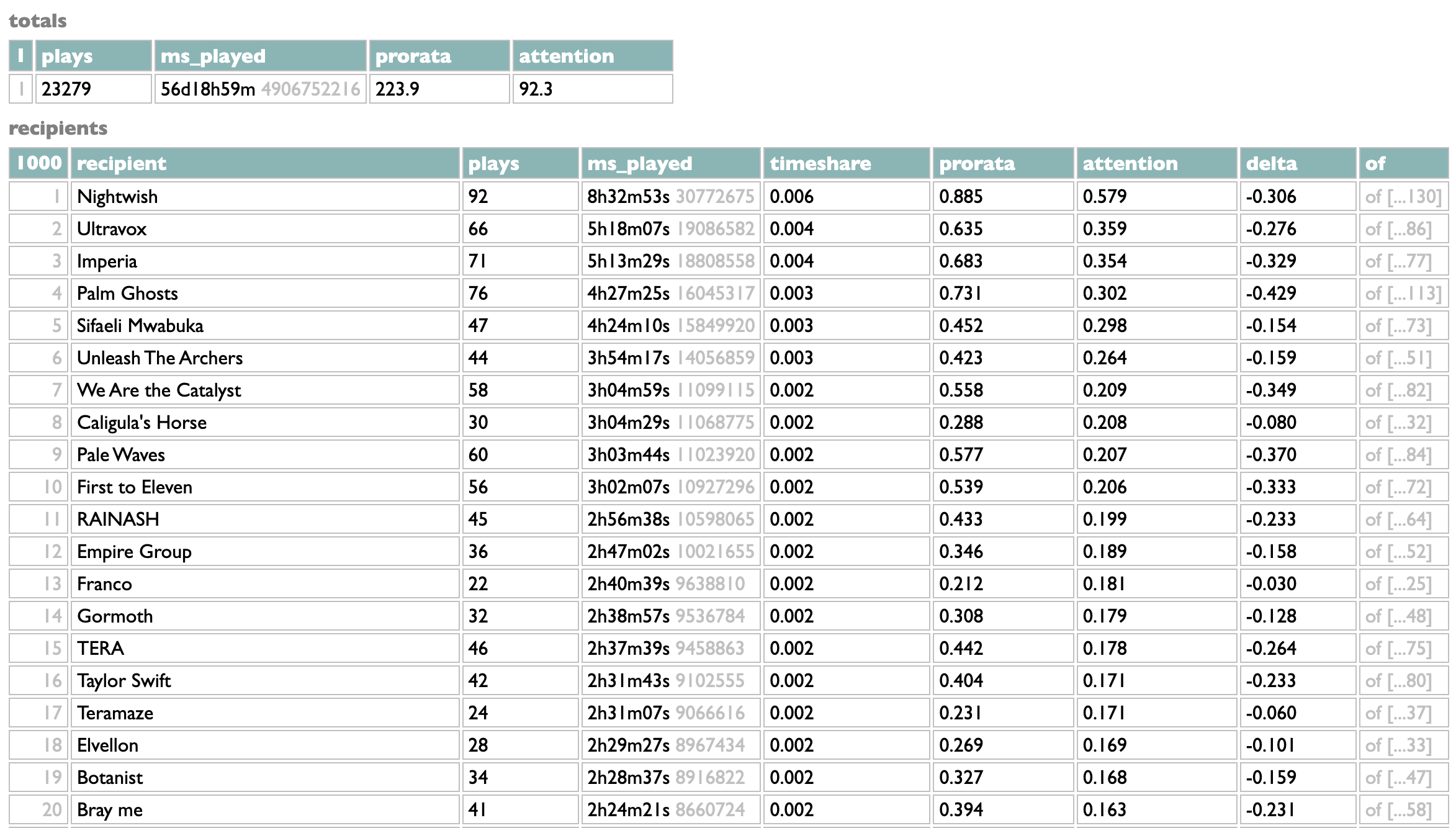
As I explain in the book, you can think of the pro-rata scheme as essentially allowing listeners who accumulate more than the average number of plays to reassign the leftover money from the people who play less than the average. User-centric models, whether based on plays or time, always only pay your artists with your money. With these hypothetical numbers, my subscription would have generated $92.30 in distributable money over the course of the year, and in the attention model that's exactly what my artists get in total. Because I happen to play very considerably more than the average listener, though, the pro-rata model allows me to commandeer almost an additional subscription and a half of money from less-active listeners, and my artists get a total of $223.90. The artists here at the top of my list benefit dramatically from this, at least proportionally, with some of them getting more than twice as much money because of me than they could get strictly from me.
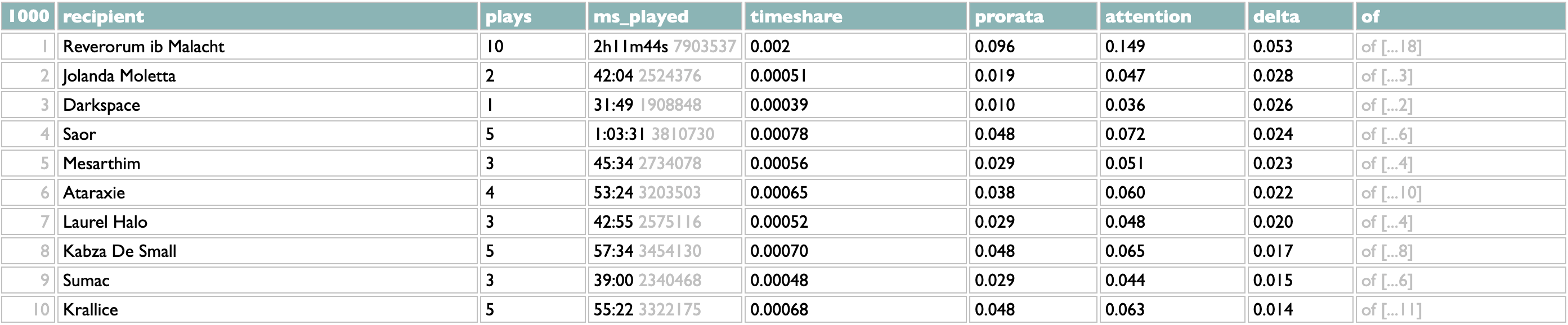
In my case this dynamic renders the plays-vs-time difference itself largely moot, but if we sort with #delta instead of #attention we can see that there are a few artists whose penchant for long tracks causes them to be under-rewarded by the current play-based scheme, and treated arguably more fairly by the time-based attention scheme:
In case it hasn't registered because I haven't bothered to implement currency-formatting, though, the decimal numbers in the prorata, attention and delta columns are all fractions of a dollar. My listening is even more obdurately broad than it is voluminous (I listened at least momentarily to 8374 different artists last year, and 5289 even if you only count the ones where I played at least :30 of at least one song), so no individual artist earns much from my streaming. Your artist amounts are likely to be higher. There's probably some selection bias such that people willing to go through the trouble of requesting their listening history, and signing up for an API key in order to use Curio, are more likely to also be more active listeners than the average. And more active listeners also tend, in general, to listen more broadly than less-active listeners. But I am, or at least I was back when I could check because of course I checked, an extreme case.
And because this is all just a query, not anything hard-coded into Curio itself, you can also experiment with the query itself to try other models if you want. I'm not really expecting you to have other streaming-royalty allocation schemes casually in mind, but I am hoping that showing you what you could try will make you slightly more likely to want to try things, in this domain or some other one you know and care about the way I know and care about music. I want a world in which the rules embedded in the systems that affect our money and our lives are intelligble to us, and subject to our verification and variation. I want us to want a better world, and we can't improve what we can't control, and we can't control what we can't understand or discuss.
† The critical caveat about the recipients here is that the current streaming services do not pay artists, they pay licensors. For independent artists, those licensors may be self-serve distributors like DistroKid or OneRPM that take only small fees and pass along most of the money to the artists. For artists on major labels, the label may keep most or even all of this royalty money, but in turn may have already paid the artist an advance against it. So the mechanics are complicated in ways that are out of both your and the streaming service's control.
‡ The trivial caveat about the query-modeling here is that the listening-history data Spotify lets you download does not identify each track's artist by unique ID, only by name. It's possible to get the correct unique artists by looking up the tracks within the query, e.g.:
but my own listening history has a lot of tracks and I didn't want to wait for that many API calls, so for this query I've chosen to tolerate the approximation of artist names. If you happen to really like multiple different artists with the exact same name, you'll see that their data gets combined in this query. I invite you into my experiment, but the invitation includes a hammer.
(And to admit my meta-interest, since I'm currently working on human computational agency and collective knowledge more than on streaming-royalty allocation, it's my belief that we should always insist that arguments based on data be supported by demonstration, not illustration. Shared understanding beats adversarial persuasion.)
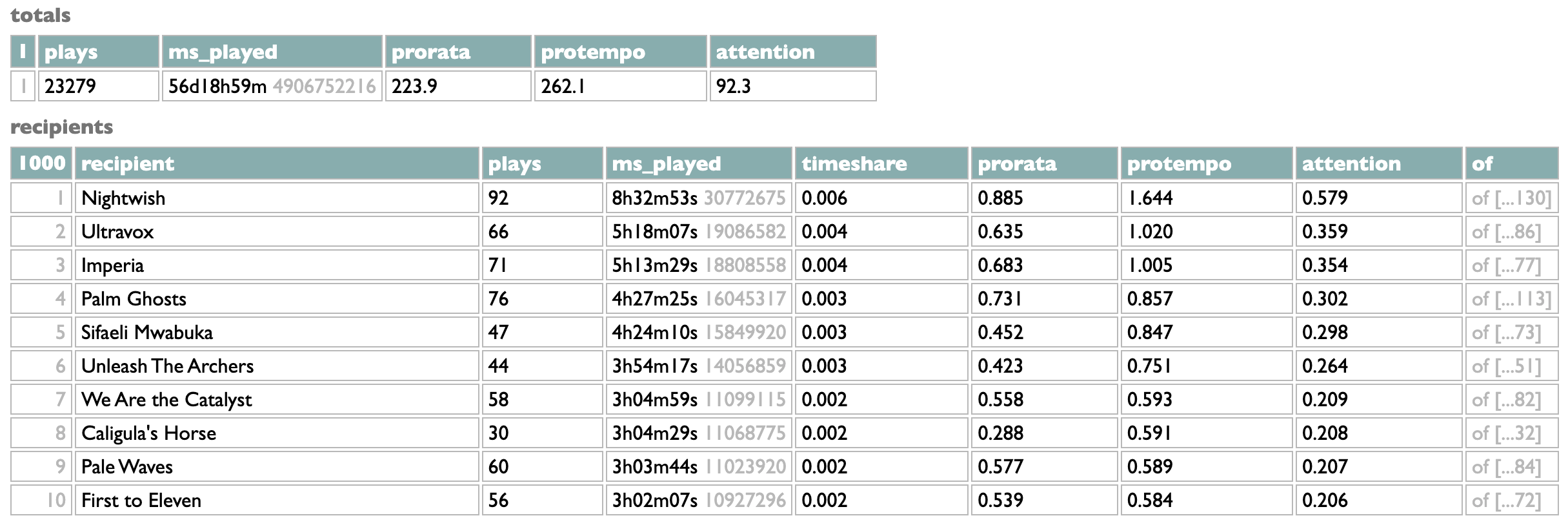
PS: To complicate this further, the scheme I actually endorse is pro-tempo, which is pro-rata but allocated by time instead of plays. This requires another guess at the average duration of a stream (not of a song), but if I put that guess at 3:00, my personal listening is even further above average in time than it is in plays, and the three-way comparison query shows me directing the allocation of $262.10, and almost 3x as much to my top artist as the supposedly-artist-centric attention scheme:
But if you've requested your own streaming history from Spotify, and loaded it into Curio, you can at least explore how alternate distribution models might distribute your money to the artists † ‡ you love.
You can start with this query comparing the usual pro-rata scheme to one that distibutes each listener's money according to their individual listening-time per artist.
Here's the query:
?listening history:~<[2024]
:(.master_metadata_album_artist_name)
??rates=(....||subscription=[=0.7*12*10.99],spu=[=800*12],rps=[=subscription/spu]),
totalms=(....ms_played,total),
pro rata=(
:ms_played>=30000:(.spotify_track_uri)
/recipient=master_metadata_album_artist_name,count=plays
.(....recipient,plays,prorata=(....plays,(rates.rps),product))
),
by user=(
/recipient=(.master_metadata_album_artist_name)
||ms_played=(..of....ms_played,total),
timeshare=[=ms_played/totalms],
subscription=(rates.subscription),
attention=[=timeshare*subscription],
-name,-key,-subscription,-count
)
?pro rata,by user//recipient #attention
||prorata=(.prorata;(0)),delta=[=attention-prorata]
||recipient,plays,ms_played,timeshare,prorata,attention,delta
...multi=(1),
totals=(
....plays=(....plays,total),
ms_played=(....ms_played,total),
prorata=(....prorata,total),
attention=(....attention,total)
),
recipients=_
:(.master_metadata_album_artist_name)
??rates=(....||subscription=[=0.7*12*10.99],spu=[=800*12],rps=[=subscription/spu]),
totalms=(....ms_played,total),
pro rata=(
:ms_played>=30000:(.spotify_track_uri)
/recipient=master_metadata_album_artist_name,count=plays
.(....recipient,plays,prorata=(....plays,(rates.rps),product))
),
by user=(
/recipient=(.master_metadata_album_artist_name)
||ms_played=(..of....ms_played,total),
timeshare=[=ms_played/totalms],
subscription=(rates.subscription),
attention=[=timeshare*subscription],
-name,-key,-subscription,-count
)
?pro rata,by user//recipient #attention
||prorata=(.prorata;(0)),delta=[=attention-prorata]
||recipient,plays,ms_played,timeshare,prorata,attention,delta
...multi=(1),
totals=(
....plays=(....plays,total),
ms_played=(....ms_played,total),
prorata=(....prorata,total),
attention=(....attention,total)
),
recipients=_
To do this without access to proprietary business data, we have to make a couple legally-arbitrary assumptions about two key internal Spotify numbers.
One is the fraction of Spotify revenue, for your subscription country and type, that gets paid out to licensors. This is variously quoted as "more than two-thirds" or "about 70%" in the press, and the exact number depends in a complicated way on local statutory rates, licensor deals and even sometimes the complicity of specific labels or artists in Spotify's grim attempts to fractionally improve their own margins. You can make up your own mind about what you want to believe this number to be, and if your mind makes up some number other than 0.7, you should replace the 0.7 in the ??rates= line with your alternative.
The second number is the average number of plays (industry-defined as "you listened to at least :30 of a song, but it doesn't make any difference how much if it's at least that much") for your subscription country and type. One common public guess at this average across all Spotify listeners is 500 plays/month; total Spotify membership is weighted about 3:2 in favor of ad-subsidized "free" listeners over subscribers; Daniel Ek once said in public that premium listeners spend about 3x as much time listening as free listeners, on average. Putting these numbers together with math (not shown here) suggests a premium-user average somewhere around 800. If you don't like that 800, replace the 800 in that same line with whatever you like better.
The 10.99 in my example is the current monthly cost of a US Basic account, which I choose (in both the moral and exemplary senses) because Spotify is engaged in a disingenuous ongoing effort to define the nominal Premium account as a supposedly-equal-value bundle of music and audiobooks so that they don't have to pay as much in music-publishing royalties. In this particular example I have filtered my listening history to data from calendar 2024, and thus have multiplied the monthly subscription and stream-count numbers both by 12. You could also take both 12s out and filter to any single month.
Using these numbers, here's what I get for my own 2024:
As I explain in the book, you can think of the pro-rata scheme as essentially allowing listeners who accumulate more than the average number of plays to reassign the leftover money from the people who play less than the average. User-centric models, whether based on plays or time, always only pay your artists with your money. With these hypothetical numbers, my subscription would have generated $92.30 in distributable money over the course of the year, and in the attention model that's exactly what my artists get in total. Because I happen to play very considerably more than the average listener, though, the pro-rata model allows me to commandeer almost an additional subscription and a half of money from less-active listeners, and my artists get a total of $223.90. The artists here at the top of my list benefit dramatically from this, at least proportionally, with some of them getting more than twice as much money because of me than they could get strictly from me.
In my case this dynamic renders the plays-vs-time difference itself largely moot, but if we sort with #delta instead of #attention we can see that there are a few artists whose penchant for long tracks causes them to be under-rewarded by the current play-based scheme, and treated arguably more fairly by the time-based attention scheme:
In case it hasn't registered because I haven't bothered to implement currency-formatting, though, the decimal numbers in the prorata, attention and delta columns are all fractions of a dollar. My listening is even more obdurately broad than it is voluminous (I listened at least momentarily to 8374 different artists last year, and 5289 even if you only count the ones where I played at least :30 of at least one song), so no individual artist earns much from my streaming. Your artist amounts are likely to be higher. There's probably some selection bias such that people willing to go through the trouble of requesting their listening history, and signing up for an API key in order to use Curio, are more likely to also be more active listeners than the average. And more active listeners also tend, in general, to listen more broadly than less-active listeners. But I am, or at least I was back when I could check because of course I checked, an extreme case.
And because this is all just a query, not anything hard-coded into Curio itself, you can also experiment with the query itself to try other models if you want. I'm not really expecting you to have other streaming-royalty allocation schemes casually in mind, but I am hoping that showing you what you could try will make you slightly more likely to want to try things, in this domain or some other one you know and care about the way I know and care about music. I want a world in which the rules embedded in the systems that affect our money and our lives are intelligble to us, and subject to our verification and variation. I want us to want a better world, and we can't improve what we can't control, and we can't control what we can't understand or discuss.
† The critical caveat about the recipients here is that the current streaming services do not pay artists, they pay licensors. For independent artists, those licensors may be self-serve distributors like DistroKid or OneRPM that take only small fees and pass along most of the money to the artists. For artists on major labels, the label may keep most or even all of this royalty money, but in turn may have already paid the artist an advance against it. So the mechanics are complicated in ways that are out of both your and the streaming service's control.
‡ The trivial caveat about the query-modeling here is that the listening-history data Spotify lets you download does not identify each track's artist by unique ID, only by name. It's possible to get the correct unique artists by looking up the tracks within the query, e.g.:
listening history :@<=10
||id=(....spotify_track_uri,([:]),split:@3)
/artist=(.other tracks.(.artists:@1))
||id=(....spotify_track_uri,([:]),split:@3)
/artist=(.other tracks.(.artists:@1))
but my own listening history has a lot of tracks and I didn't want to wait for that many API calls, so for this query I've chosen to tolerate the approximation of artist names. If you happen to really like multiple different artists with the exact same name, you'll see that their data gets combined in this query. I invite you into my experiment, but the invitation includes a hammer.
(And to admit my meta-interest, since I'm currently working on human computational agency and collective knowledge more than on streaming-royalty allocation, it's my belief that we should always insist that arguments based on data be supported by demonstration, not illustration. Shared understanding beats adversarial persuasion.)
PS: To complicate this further, the scheme I actually endorse is pro-tempo, which is pro-rata but allocated by time instead of plays. This requires another guess at the average duration of a stream (not of a song), but if I put that guess at 3:00, my personal listening is even further above average in time than it is in plays, and the three-way comparison query shows me directing the allocation of $262.10, and almost 3x as much to my top artist as the supposedly-artist-centric attention scheme: