
In Query geekery motivated by music geekery I describe this DACTAL implementation of a genre-clustering algorithm:
The clustering in this version makes heavy use of the DACTAL set-labeling feature, which assigns names to sets of data and allows them to be retrieved by name later. That's what all the ?artistsx=, ?clusters= and similar bits are doing.
But it also uses DACTAL's feature for creating data inline. That's what the four-line block beginning with ...top genres= is doing. The difference between the two features is immediately evident if we try to scrutinize this query more closely by changing the ! at the end to !1 so it only runs one iteration. We get this:
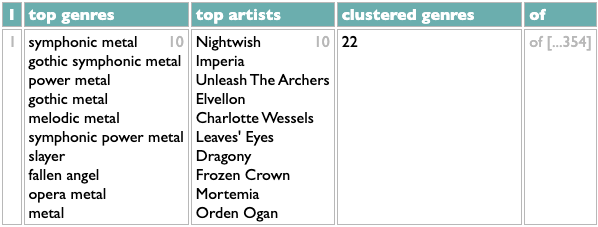
That is, indeed, the first row of the query's results, and the lines in the query's ... operation map directly to the columns you see. But when I said I wanted to look at this query "more closely", I didn't mean I just wanted to see less of it. The crucial second piece of this query's clustering operation is the queue of unclustered artists, which gets shortened after each step. The query handles this queue by using set-labeling to stash it away as "artistsx" at two points in the query and get it back at two other points. This is useful, but it's also invisible. If I want to see the state of the queue after the first step I have to do something extra to pull it back out of the ether. E.g.:

Aha! Not hard. But really, when you're working with data and algorithms, your life will be a lot easier if you assume from the beginning that you'll probably end up wanting to look inside everything. Our lives mediated by data algorithms would all be improved if it were easier for the people who work on those algorithms to look inside of them, and to show us what's happening inside.
So instead of just using ... diagnostically at the end of the query, what if we built the whole query that way to begin with?
The logic for picking the next cluster is still complicated, but the same as before except for the very beginning where it gets the contents of the queue. I've defined it in advance in this version, since I implemented that feature since the earlier post, which allows the actual iterative repeat at the bottom to be written more clearly. We start with an empty cluster list and a full queue, and each iteration adds the next cluster to the cluster list, and then removes its artists from the queue. Here's what we see after one iteration, just by virtue of having interrupted the query with !1:

If you don't want to squint, it's the same. The results are the same, but the process is easier to inspect.
The new query is also faster than the old query, but not because of the invisible/visible thing. In general, extra visibility tends to cost a little more in processing time. The old version was slower than it should have been, by virtue of being too casual about how the clusters were identified, but got away with it because the extra data that might have slowed the process down was hidden. The new version is more diligent about this because it has to be (thus the id=(.clusters...._count) part), and indeed backporting that tweak to the old version does make it faster than the new version. But only by milliseconds. If it's hard for you to tell what you're doing, you'll eventually do it wrong, and the days you will waste laboriously figuring out how will be longer, and more miserable, than the milliseconds you thought you were saving.
PS: Although it seems likely that nobody other than me has yet intentionally instigated a DACTAL repeat, I will note for the record that I have changed the rules for the repeat operator since introducing it, and both this post and the linked earlier one now demonstrate the new design. The operator is now !, instead of ??, and it now always repeats the previous single operation, whereas in its first iteration it always appeared at the end of a subquery, and repeated that subquery. So, e.g., recursive reply-expansion was originally
and that exact structure would now be written
but since in this particular case the subquery has only a single operation, this query can now be written as just
?artistsx=(2024 artists scored|genre=(.id.artist genres.genres),weight=(....artistpoints,sqrt))
?genre index=(artistsx/genre,of=artists:count>=5)
?clusters=()
?(
?artistsx=(artistsx:-~~(clusters:@@1.of))
?nextgenre=(artistsx/genre,of=artists:count>=10#(.artists....weight,total),count:@1)
?nextcluster=(
nextgenre.artists/genre,of=artists:count>=5
||total=(.genre.genre index.count),overlap=[=count/total]
:(.total) :overlap>=[.1] #(.artists....weight,total),count
...top genres=(.genre:@<=10),
top artists=(.artists:@<=10.name),
clustered genres=(.genre....count),
of=(.genre.genre index.artists)
:(.top genres)
)
?clusters=(clusters,nextcluster)
)!
?genre index=(artistsx/genre,of=artists:count>=5)
?clusters=()
?(
?artistsx=(artistsx:-~~(clusters:@@1.of))
?nextgenre=(artistsx/genre,of=artists:count>=10#(.artists....weight,total),count:@1)
?nextcluster=(
nextgenre.artists/genre,of=artists:count>=5
||total=(.genre.genre index.count),overlap=[=count/total]
:(.total) :overlap>=[.1] #(.artists....weight,total),count
...top genres=(.genre:@<=10),
top artists=(.artists:@<=10.name),
clustered genres=(.genre....count),
of=(.genre.genre index.artists)
:(.top genres)
)
?clusters=(clusters,nextcluster)
)!
The clustering in this version makes heavy use of the DACTAL set-labeling feature, which assigns names to sets of data and allows them to be retrieved by name later. That's what all the ?artistsx=, ?clusters= and similar bits are doing.
But it also uses DACTAL's feature for creating data inline. That's what the four-line block beginning with ...top genres= is doing. The difference between the two features is immediately evident if we try to scrutinize this query more closely by changing the ! at the end to !1 so it only runs one iteration. We get this:
That is, indeed, the first row of the query's results, and the lines in the query's ... operation map directly to the columns you see. But when I said I wanted to look at this query "more closely", I didn't mean I just wanted to see less of it. The crucial second piece of this query's clustering operation is the queue of unclustered artists, which gets shortened after each step. The query handles this queue by using set-labeling to stash it away as "artistsx" at two points in the query and get it back at two other points. This is useful, but it's also invisible. If I want to see the state of the queue after the first step I have to do something extra to pull it back out of the ether. E.g.:
?artistsx=(2024 artists scored|genre=(.id.artist genres.genres),weight=(....artistpoints,sqrt))
?genre index=(artistsx/genre,of=artists:count>=5)
?clusters=()
?(
?artistsx=(artistsx:-~~(clusters:@@1.of))
?nextgenre=(artistsx/genre,of=artists:count>=10#(.artists....weight,total),count:@1)
?nextcluster=(
nextgenre.artists/genre,of=artists:count>=5
||total=(.genre.genre index.count),overlap=[=count/total]
:(.total) :overlap>=[.1] #(.artists....weight,total),count
...top genres=(.genre:@<=10),
top artists=(.artists:@<=10.name),
clustered genres=(.genre....count),
of=(.genre.genre index.artists)
:(.top genres)
)
?clusters=(clusters,nextcluster)
)!1
...clusters=(clusters),queue=(artistsx)
?genre index=(artistsx/genre,of=artists:count>=5)
?clusters=()
?(
?artistsx=(artistsx:-~~(clusters:@@1.of))
?nextgenre=(artistsx/genre,of=artists:count>=10#(.artists....weight,total),count:@1)
?nextcluster=(
nextgenre.artists/genre,of=artists:count>=5
||total=(.genre.genre index.count),overlap=[=count/total]
:(.total) :overlap>=[.1] #(.artists....weight,total),count
...top genres=(.genre:@<=10),
top artists=(.artists:@<=10.name),
clustered genres=(.genre....count),
of=(.genre.genre index.artists)
:(.top genres)
)
?clusters=(clusters,nextcluster)
)!1
...clusters=(clusters),queue=(artistsx)
Aha! Not hard. But really, when you're working with data and algorithms, your life will be a lot easier if you assume from the beginning that you'll probably end up wanting to look inside everything. Our lives mediated by data algorithms would all be improved if it were easier for the people who work on those algorithms to look inside of them, and to show us what's happening inside.
So instead of just using ... diagnostically at the end of the query, what if we built the whole query that way to begin with?
|nextcluster=>(
.queue/genre,of=artists:count>=10#(.artists....weight,total),count:@1
.artists/genre,of=artists:count>=5
||total=(.genre.genre index.count),overlap=[=count/total]
:(.total) :overlap>=[.1] #(.artists....weight,total),count
...name=(.genre:@1),
top genres=(.genre:@<=10),
top artists=(.artists:@<=10.name),
clustered genres=(.genre....count),
of=(.genre.genre index.artists)
:(.top genres)
)
?artistsx=(2024 artists scored|genre=(.id.artist genres.genres),weight=(....artistpoints,sqrt))
?genre index=(artistsx/genre,of=artists:count>=5)
...clusters=(),queue=(artistsx)
|clusters=+(.nextcluster),
queue=-(.clusters:@@1.of),
id=(.clusters...._count)
!1
.queue/genre,of=artists:count>=10#(.artists....weight,total),count:@1
.artists/genre,of=artists:count>=5
||total=(.genre.genre index.count),overlap=[=count/total]
:(.total) :overlap>=[.1] #(.artists....weight,total),count
...name=(.genre:@1),
top genres=(.genre:@<=10),
top artists=(.artists:@<=10.name),
clustered genres=(.genre....count),
of=(.genre.genre index.artists)
:(.top genres)
)
?artistsx=(2024 artists scored|genre=(.id.artist genres.genres),weight=(....artistpoints,sqrt))
?genre index=(artistsx/genre,of=artists:count>=5)
...clusters=(),queue=(artistsx)
|clusters=+(.nextcluster),
queue=-(.clusters:@@1.of),
id=(.clusters...._count)
!1
The logic for picking the next cluster is still complicated, but the same as before except for the very beginning where it gets the contents of the queue. I've defined it in advance in this version, since I implemented that feature since the earlier post, which allows the actual iterative repeat at the bottom to be written more clearly. We start with an empty cluster list and a full queue, and each iteration adds the next cluster to the cluster list, and then removes its artists from the queue. Here's what we see after one iteration, just by virtue of having interrupted the query with !1:
If you don't want to squint, it's the same. The results are the same, but the process is easier to inspect.
The new query is also faster than the old query, but not because of the invisible/visible thing. In general, extra visibility tends to cost a little more in processing time. The old version was slower than it should have been, by virtue of being too casual about how the clusters were identified, but got away with it because the extra data that might have slowed the process down was hidden. The new version is more diligent about this because it has to be (thus the id=(.clusters...._count) part), and indeed backporting that tweak to the old version does make it faster than the new version. But only by milliseconds. If it's hard for you to tell what you're doing, you'll eventually do it wrong, and the days you will waste laboriously figuring out how will be longer, and more miserable, than the milliseconds you thought you were saving.
PS: Although it seems likely that nobody other than me has yet intentionally instigated a DACTAL repeat, I will note for the record that I have changed the rules for the repeat operator since introducing it, and both this post and the linked earlier one now demonstrate the new design. The operator is now !, instead of ??, and it now always repeats the previous single operation, whereas in its first iteration it always appeared at the end of a subquery, and repeated that subquery. So, e.g., recursive reply-expansion was originally
messages.(._,replies??)
and that exact structure would now be written
messages.(._,replies)!
but since in this particular case the subquery has only a single operation, this query can now be written as just
messages._,replies!