
14 January 2025 to 6 November 2024
¶ What we know · 14 January 2025 listen/tech
The thing I worked on the longest, in my Echo Nest / Spotify time, was calculating artist similarity. In the Echo Nest days, when we didn't have direct listening data, we derived scores for pairs of artists based on patterns of shared descriptive words found in web pages about each of them. Or, more accurately, web pages maybe about them, because figuring out whether any given blob of text that contains a given string of letters is about a band whose name is that same string of letters, at all never mind in a descriptively useful sense, is hard.
Once we got swallowed by Spotify, of course, we had all the listening-data plankton we could krill. The goal of "collaborative filtering", taken most lowercasely, is to extract collective knowledge from collected data. The Spotify feature this work powered was called (eventually) Fans Also Like, and one of my greatest organizational triumphs at Spotify was that after many years of technical work and political lobbying, I succeeded in making this feature live up to its name. For about a year and a half, starting around April 2023, the Spotify artist page Fans Also Like lists were really an algebraic formulation of getting each artist's fans, not just listeners, and finding out what other artists they disproportionately also liked. And nothing else. You only saw the first 20 results for each artist, but the underlying dataset behind this went deeper, and I think was a genuinely unprecedented collective cultural achievement of the Spotify audience.
Most of the complexity of doing this well, if by "well" you mean reflecting actual patterns of human interest as opposed to round-off error in vector embeddings or clandestine margin-chiseling, which you should, was actually in the quantification of "fan". I would not be able to explain all the details of that process from memory, even if I were allowed to, but the core idea is that the more you raise the threshold of fandom, the better similarity signal you get from the listening patterns of those fans, but the fewer artists are included, so if you want both precision and recall, you have to get creative.
And of course you have to get data, to begin with. We cannot recreate the lost Fans Also Like network from outside of Spotify, because we cannot get their dataset of fan/artist pairs. Or, really, our dataset, because it's our listening.
If you happen to have pairs of any kind of data, though, doing simple math to extract similarity of one half of those pairs based on the co-reference patterns of the other half is easy. In fact, if you have that pair data in JSON, you can load it into the spec/doc/test/playground page for Dactal and do it right now.
For example, over at AlbumOfTheYear.org they aggregate album-of-the-year lists from many other publications and produce a scored meta-ranking of the year's albums. But this dataset of publication/album pairs also encodes patterns of implicit knowledge about album similarity based on the tendencies of publications to list albums together, and about publication similarity based on the tendencies of albums to appeal to publications together.
Here's how to extract it using Dactal:
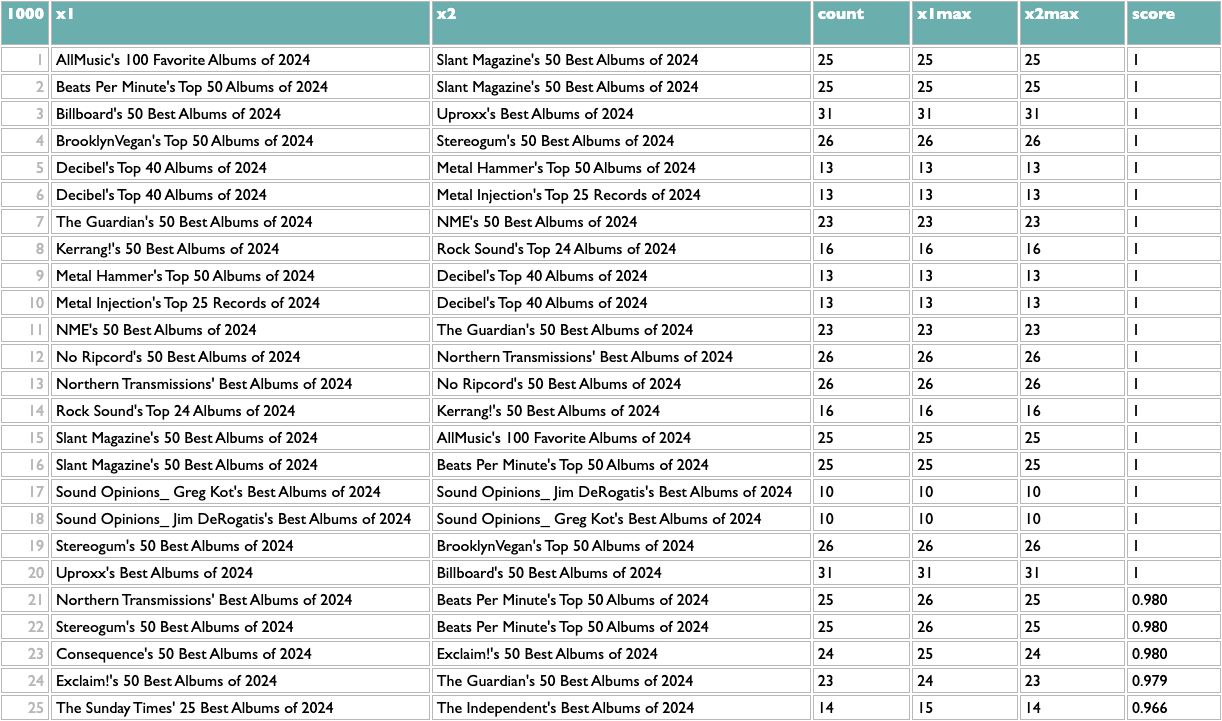
The first orange line is specific to this data, my extraction from the AOTY lists, but all it needs to produce is a two-column list with x and y. Like this:
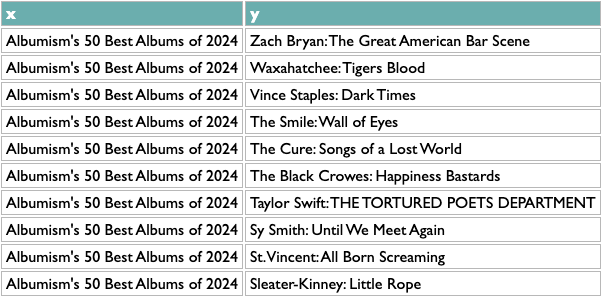
Once you have any x/y list like this, the rest of the query works the same. The scoring logic here (which isn't what I used at Spotify, but you probably aren't dealing with 600 million people listening to 10 million artists) counts the overlap between any pair of x based on y, and then scales that by the maximum overlaps of both parts of the pair. So a score of 1 means that both things in that pair are each other's closest match. The calculation is asymmetric because one part of a pair may be the other's closest match but not vice versa. If you read about music online you may know that, e.g., Decibel and Metal Hammer are both metal-specific, The Guardian and NME are both British, and BrooklynVegan and Stereogum are both read by the kind of people who read BrooklynVegan and Stereogum, so the top of those results passes a basic sanity check.
And because everything but the first line is independent of what x and y are, that means we can flip x and y (just those two letters!) and get album similarity:
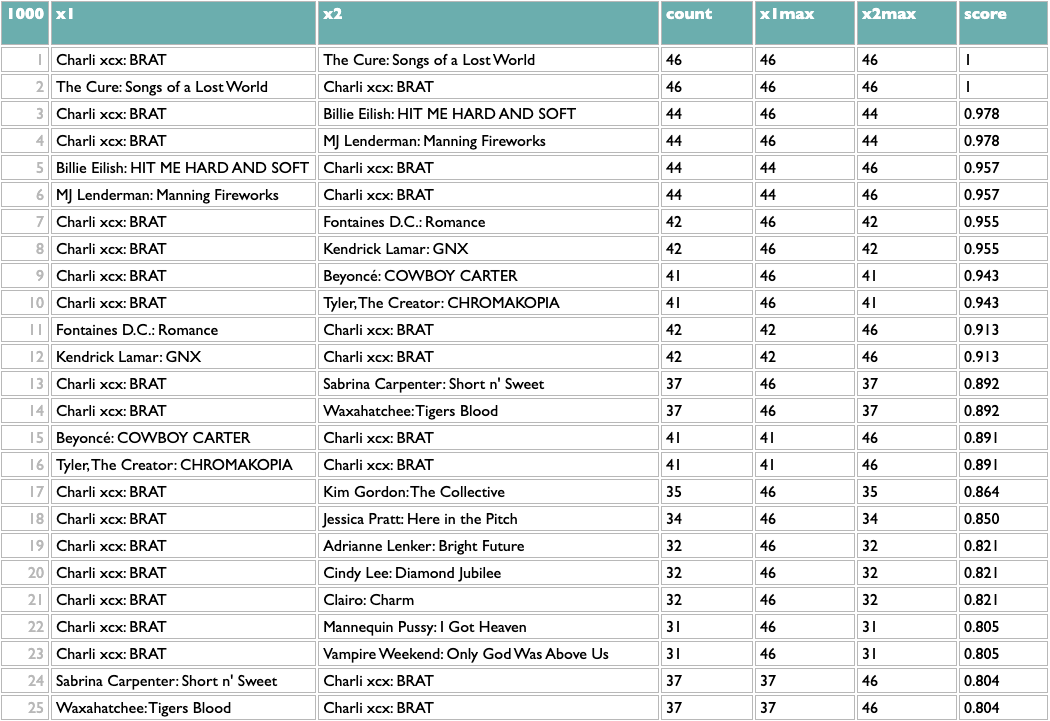
This passes a sanity check – everybody who writes about music likes Charli – but not an interestingness check, so we might opt to filter out BRAT just to see what else we can learn:
Not bad! The two Future/Metro Boomin albums are most similar to each other, which is the good kind of confidence-boosting boring answer, but a bunch of the other pairs are plausible yet non-obvious: two indie rock records, two UK indie guitar records, two indie rappers, two metal-adjacent records.
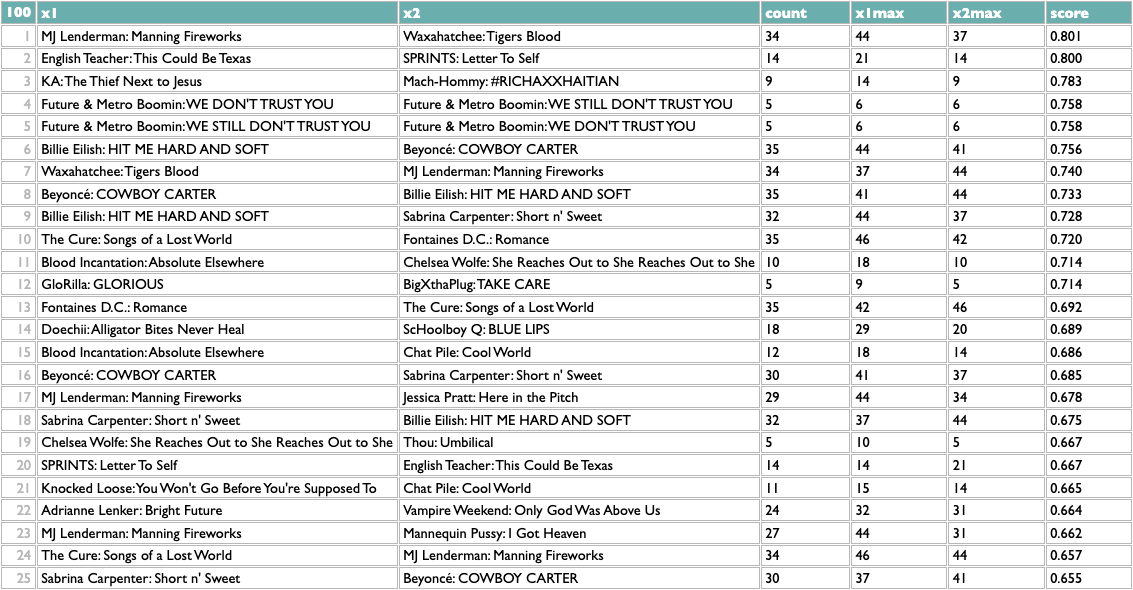
These scores are normalized locally, not globally, so the real way to use them is to reorganize this by album. Which is also easy:
That's interesting to me. What's interesting to you?
[PS: Oh, here, I put this dataset up in raw interactive form, so you can play with it yourself if you want.]
Once we got swallowed by Spotify, of course, we had all the listening-data plankton we could krill. The goal of "collaborative filtering", taken most lowercasely, is to extract collective knowledge from collected data. The Spotify feature this work powered was called (eventually) Fans Also Like, and one of my greatest organizational triumphs at Spotify was that after many years of technical work and political lobbying, I succeeded in making this feature live up to its name. For about a year and a half, starting around April 2023, the Spotify artist page Fans Also Like lists were really an algebraic formulation of getting each artist's fans, not just listeners, and finding out what other artists they disproportionately also liked. And nothing else. You only saw the first 20 results for each artist, but the underlying dataset behind this went deeper, and I think was a genuinely unprecedented collective cultural achievement of the Spotify audience.
Most of the complexity of doing this well, if by "well" you mean reflecting actual patterns of human interest as opposed to round-off error in vector embeddings or clandestine margin-chiseling, which you should, was actually in the quantification of "fan". I would not be able to explain all the details of that process from memory, even if I were allowed to, but the core idea is that the more you raise the threshold of fandom, the better similarity signal you get from the listening patterns of those fans, but the fewer artists are included, so if you want both precision and recall, you have to get creative.
And of course you have to get data, to begin with. We cannot recreate the lost Fans Also Like network from outside of Spotify, because we cannot get their dataset of fan/artist pairs. Or, really, our dataset, because it's our listening.
If you happen to have pairs of any kind of data, though, doing simple math to extract similarity of one half of those pairs based on the co-reference patterns of the other half is easy. In fact, if you have that pair data in JSON, you can load it into the spec/doc/test/playground page for Dactal and do it right now.
For example, over at AlbumOfTheYear.org they aggregate album-of-the-year lists from many other publications and produce a scored meta-ranking of the year's albums. But this dataset of publication/album pairs also encodes patterns of implicit knowledge about album similarity based on the tendencies of publications to list albums together, and about publication similarity based on the tendencies of albums to appeal to publications together.
Here's how to extract it using Dactal:
?data=(aoty.entries.(....x=aotylist,y=albumkey))
?paircounts=(data/y/x1=(.of.x),x2=(.of.x):(.key:@2):count>=5)
?x maxpoints=(paircounts/key||maxpoints=(.of.count....max))
?paircounts
||x1max=(.x1.x maxpoints.maxpoints),
x2max=(.x2.x maxpoints.maxpoints),
score=[=2*count**2/((count+x1max)*x2max)]
#score
?paircounts=(data/y/x1=(.of.x),x2=(.of.x):(.key:@2):count>=5)
?x maxpoints=(paircounts/key||maxpoints=(.of.count....max))
?paircounts
||x1max=(.x1.x maxpoints.maxpoints),
x2max=(.x2.x maxpoints.maxpoints),
score=[=2*count**2/((count+x1max)*x2max)]
#score

The first orange line is specific to this data, my extraction from the AOTY lists, but all it needs to produce is a two-column list with x and y. Like this:
?data=(aoty.entries.(....x=aotylist,y=albumkey))

Once you have any x/y list like this, the rest of the query works the same. The scoring logic here (which isn't what I used at Spotify, but you probably aren't dealing with 600 million people listening to 10 million artists) counts the overlap between any pair of x based on y, and then scales that by the maximum overlaps of both parts of the pair. So a score of 1 means that both things in that pair are each other's closest match. The calculation is asymmetric because one part of a pair may be the other's closest match but not vice versa. If you read about music online you may know that, e.g., Decibel and Metal Hammer are both metal-specific, The Guardian and NME are both British, and BrooklynVegan and Stereogum are both read by the kind of people who read BrooklynVegan and Stereogum, so the top of those results passes a basic sanity check.
And because everything but the first line is independent of what x and y are, that means we can flip x and y (just those two letters!) and get album similarity:
?data=(aoty.entries.(....y=aotylist,x=albumkey))
?paircounts=(data/y/x1=(.of.x),x2=(.of.x):(.key:@2):count>=5)
?x maxpoints=(paircounts/key||maxpoints=(.of.count....max))
?paircounts
||x1max=(.x1.x maxpoints.maxpoints),
x2max=(.x2.x maxpoints.maxpoints),
score=[=2*count**2/((count+x1max)*x2max)]
#score
?paircounts=(data/y/x1=(.of.x),x2=(.of.x):(.key:@2):count>=5)
?x maxpoints=(paircounts/key||maxpoints=(.of.count....max))
?paircounts
||x1max=(.x1.x maxpoints.maxpoints),
x2max=(.x2.x maxpoints.maxpoints),
score=[=2*count**2/((count+x1max)*x2max)]
#score

This passes a sanity check – everybody who writes about music likes Charli – but not an interestingness check, so we might opt to filter out BRAT just to see what else we can learn:
?data=(aoty.entries.(....y=aotylist,x=albumkey))
?paircounts=(data/y/x1=(.of.x),x2=(.of.x):(.key:@2):count>=5)
?x maxpoints=(paircounts/key||maxpoints=(.of.count....max))
?paircounts
||x1max=(.x1.x maxpoints.maxpoints),
x2max=(.x2.x maxpoints.maxpoints),
score=[=2*count**2/((count+x1max)*x2max)]
:-(.x1,x2:=[Charli xcx: BRAT])
#score
?paircounts=(data/y/x1=(.of.x),x2=(.of.x):(.key:@2):count>=5)
?x maxpoints=(paircounts/key||maxpoints=(.of.count....max))
?paircounts
||x1max=(.x1.x maxpoints.maxpoints),
x2max=(.x2.x maxpoints.maxpoints),
score=[=2*count**2/((count+x1max)*x2max)]
:-(.x1,x2:=[Charli xcx: BRAT])
#score

Not bad! The two Future/Metro Boomin albums are most similar to each other, which is the good kind of confidence-boosting boring answer, but a bunch of the other pairs are plausible yet non-obvious: two indie rock records, two UK indie guitar records, two indie rappers, two metal-adjacent records.
These scores are normalized locally, not globally, so the real way to use them is to reorganize this by album. Which is also easy:
?data=(aoty.entries.(....y=aotylist,x=albumkey))
?paircounts=(data/y/x1=(.of.x),x2=(.of.x):(.key:@2):count>=5)
?x maxpoints=(paircounts/key||maxpoints=(.of.count....max))
?paircounts
||x1max=(.x1.x maxpoints.maxpoints),
x2max=(.x2.x maxpoints.maxpoints),
score=[=2*count**2/((count+x1max)*x2max)]
:-(.x1,x2:=[Charli xcx: BRAT])
#score
/iyl=(.x1,x2)
.(....iyl,yml=(._,(.of.x1,x2):@>1:@<=10)
?paircounts=(data/y/x1=(.of.x),x2=(.of.x):(.key:@2):count>=5)
?x maxpoints=(paircounts/key||maxpoints=(.of.count....max))
?paircounts
||x1max=(.x1.x maxpoints.maxpoints),
x2max=(.x2.x maxpoints.maxpoints),
score=[=2*count**2/((count+x1max)*x2max)]
:-(.x1,x2:=[Charli xcx: BRAT])
#score
/iyl=(.x1,x2)
.(....iyl,yml=(._,(.of.x1,x2):@>1:@<=10)
| 146 | iyl | yml |
| 1 | A. G. Cook: Britpop | 10 Maggie Rogers: Don't Forget Me Remi Wolf: Big Ideas Clairo: Charm Jack White: No Name Magdalena Bay: Imaginal Disk Vampire Weekend: Only God Was Above Us Fontaines D.C.: Romance Doechii: Alligator Bites Never Heal Tyler, The Creator: CHROMAKOPIA ScHoolboy Q: BLUE LIPS |
| 2 | Adrianne Lenker: Bright Future | 10 Vampire Weekend: Only God Was Above Us The Last Dinner Party: Prelude to Ecstasy The Cure: Songs of a Lost World Fontaines D.C.: Romance Arooj Aftab: Night Reign Kim Gordon: The Collective Magdalena Bay: Imaginal Disk Floating Points: Cascade Waxahatchee: Tigers Blood MJ Lenderman: Manning Fireworks |
| 3 | Amyl and The Sniffers: Cartoon Darkness | 10 English Teacher: This Could Be Texas The Last Dinner Party: Prelude to Ecstasy Bob Vylan: Humble As The Sun Hamish Hawk: A Firmer Hand IDLES: TANGK SPRINTS: Letter To Self Fontaines D.C.: Romance The Cure: Songs of a Lost World Waxahatchee: Tigers Blood Wunderhorse: Midas |
| 4 | Ariana Grande: eternal sunshine | 10 Billie Eilish: HIT ME HARD AND SOFT Sabrina Carpenter: Short n' Sweet Dua Lipa: Radical Optimism Beyoncé: COWBOY CARTER Kacey Musgraves: Deeper Well Clairo: Charm Doechii: Alligator Bites Never Heal Vampire Weekend: Only God Was Above Us Magdalena Bay: Imaginal Disk The Cure: Songs of a Lost World |
| 5 | Arooj Aftab: Night Reign | 10 Adrianne Lenker: Bright Future Jessica Pratt: Here in the Pitch Beth Gibbons: Lives Outgrown Cindy Lee: Diamond Jubilee MJ Lenderman: Manning Fireworks The Cure: Songs of a Lost World Nala Sinephro: Endlessness Vampire Weekend: Only God Was Above Us Waxahatchee: Tigers Blood Nilüfer Yanya: My Method Actor |
| 6 | Astrid Sonne: Great Doubt | 4 Nala Sinephro: Endlessness Nilüfer Yanya: My Method Actor MJ Lenderman: Manning Fireworks Mk.gee: Two Star & The Dream Police |
| 7 | Being Dead: EELS | 10 This Is Lorelei: Box For Buddy, Box For Star Mannequin Pussy: I Got Heaven Jessica Pratt: Here in the Pitch Nilüfer Yanya: My Method Actor Blood Incantation: Absolute Elsewhere Magdalena Bay: Imaginal Disk Mk.gee: Two Star & The Dream Police Vampire Weekend: Only God Was Above Us MJ Lenderman: Manning Fireworks Clairo: Charm |
| 8 | Beth Gibbons: Lives Outgrown | 10 The Cure: Songs of a Lost World Arooj Aftab: Night Reign Jessica Pratt: Here in the Pitch Adrianne Lenker: Bright Future Kim Gordon: The Collective Julia Holter: Something in the Room She Moves Mannequin Pussy: I Got Heaven Waxahatchee: Tigers Blood Nilüfer Yanya: My Method Actor Chat Pile: Cool World |
| 9 | Beyoncé: COWBOY CARTER | 10 Billie Eilish: HIT ME HARD AND SOFT Sabrina Carpenter: Short n' Sweet Doechii: Alligator Bites Never Heal Kendrick Lamar: GNX Jack White: No Name The Cure: Songs of a Lost World Kali Uchis: ORQUÍDEAS Waxahatchee: Tigers Blood MJ Lenderman: Manning Fireworks ScHoolboy Q: BLUE LIPS |
| 10 | BigXthaPlug: TAKE CARE | 4 GloRilla: GLORIOUS Doechii: Alligator Bites Never Heal Tyler, The Creator: CHROMAKOPIA Kendrick Lamar: GNX |
| 11 | Bill Ryder-Jones: Iechyd Da | 10 Amyl and The Sniffers: Cartoon Darkness Arooj Aftab: Night Reign Fontaines D.C.: Romance Adrianne Lenker: Bright Future The Cure: Songs of a Lost World Kim Gordon: The Collective Beth Gibbons: Lives Outgrown The Last Dinner Party: Prelude to Ecstasy Vampire Weekend: Only God Was Above Us Cindy Lee: Diamond Jubilee |
| 12 | Billie Eilish: HIT ME HARD AND SOFT | 10 Beyoncé: COWBOY CARTER Sabrina Carpenter: Short n' Sweet The Cure: Songs of a Lost World Clairo: Charm St. Vincent: All Born Screaming Doechii: Alligator Bites Never Heal Ariana Grande: eternal sunshine Kendrick Lamar: GNX Taylor Swift: THE TORTURED POETS DEPARTMENT Kali Uchis: ORQUÍDEAS |
| 13 | Bladee: Cold Visions | 2 Mount Eerie: Night Palace Clairo: Charm |
| 14 | Blood Incantation: Absolute Elsewhere | 10 Chelsea Wolfe: She Reaches Out to She Reaches Out to She Chat Pile: Cool World Judas Priest: Invincible Shield Knocked Loose: You Won't Go Before You're Supposed To Mannequin Pussy: I Got Heaven Opeth: The Last Will and Testament Gatecreeper: Dark Superstition Thou: Umbilical Vampire Weekend: Only God Was Above Us Adrianne Lenker: Bright Future |
| 15 | Bob Vylan: Humble As The Sun | Amyl and The Sniffers: Cartoon Darkness |
| 16 | Bring Me The Horizon: POST HUMAN: NeX GEn | Knocked Loose: You Won't Go Before You're Supposed To |
| 17 | Brittany Howard: What Now | 10 Common & Pete Rock: The Auditorium Vol. 1 Waxahatchee: Tigers Blood Vampire Weekend: Only God Was Above Us Adrianne Lenker: Bright Future Billie Eilish: HIT ME HARD AND SOFT The Cure: Songs of a Lost World Beyoncé: COWBOY CARTER E L U C I D: REVELATOR ScHoolboy Q: BLUE LIPS Johnny Blue Skies: Passage du Desir |
| 18 | Caribou: Honey | 3 Kim Gordon: The Collective Waxahatchee: Tigers Blood MJ Lenderman: Manning Fireworks |
| 19 | Cassandra Jenkins: My Light, My Destroyer | 10 MJ Lenderman: Manning Fireworks Nala Sinephro: Endlessness Waxahatchee: Tigers Blood Nilüfer Yanya: My Method Actor Jessica Pratt: Here in the Pitch Kim Gordon: The Collective Mabe Fratti: Sentir Que No Sabes Arooj Aftab: Night Reign The Cure: Songs of a Lost World Mk.gee: Two Star & The Dream Police |
| 20 | Chanel Beads: Your Day Will Come | 5 Nala Sinephro: Endlessness Mk.gee: Two Star & The Dream Police Mannequin Pussy: I Got Heaven Cindy Lee: Diamond Jubilee MJ Lenderman: Manning Fireworks |
| 21 | Charli xcx: Brat and it's completely different but also still brat | 5 Doechii: Alligator Bites Never Heal Sabrina Carpenter: Short n' Sweet Beyoncé: COWBOY CARTER Billie Eilish: HIT ME HARD AND SOFT Kim Gordon: The Collective |
| 22 | Chat Pile: Cool World | 10 Blood Incantation: Absolute Elsewhere Knocked Loose: You Won't Go Before You're Supposed To Gouge Away: Deep Sage Touché Amoré: Spiral in a Straight Line Foxing: Foxing Magdalena Bay: Imaginal Disk Mannequin Pussy: I Got Heaven Cindy Lee: Diamond Jubilee Mount Eerie: Night Palace The Cure: Songs of a Lost World |
| 23 | Chelsea Wolfe: She Reaches Out to She Reaches Out to She | 10 Blood Incantation: Absolute Elsewhere Thou: Umbilical Knocked Loose: You Won't Go Before You're Supposed To Touché Amoré: Spiral in a Straight Line Geordie Greep: The New Sound Julia Holter: Something in the Room She Moves Chat Pile: Cool World Beth Gibbons: Lives Outgrown ScHoolboy Q: BLUE LIPS Mannequin Pussy: I Got Heaven |
| 24 | Chief Keef: Almighty So 2 | 10 Mk.gee: Two Star & The Dream Police Sabrina Carpenter: Short n' Sweet Nilüfer Yanya: My Method Actor Vampire Weekend: Only God Was Above Us Adrianne Lenker: Bright Future Clairo: Charm Waxahatchee: Tigers Blood Beyoncé: COWBOY CARTER Kendrick Lamar: GNX Billie Eilish: HIT ME HARD AND SOFT |
| 25 | Christopher Owens: I Wanna Run Barefoot Through Your Hair | 4 Mannequin Pussy: I Got Heaven Vampire Weekend: Only God Was Above Us MJ Lenderman: Manning Fireworks The Cure: Songs of a Lost World |
| 26 | Cindy Lee: Diamond Jubilee | 10 MJ Lenderman: Manning Fireworks Jessica Pratt: Here in the Pitch Magdalena Bay: Imaginal Disk The Cure: Songs of a Lost World Arooj Aftab: Night Reign Waxahatchee: Tigers Blood Mdou Moctar: Funeral for Justice Mount Eerie: Night Palace Mannequin Pussy: I Got Heaven Kim Gordon: The Collective |
| 27 | claire rousay: sentiment | 10 Kim Gordon: The Collective Arooj Aftab: Night Reign MJ Lenderman: Manning Fireworks Nala Sinephro: Endlessness Mk.gee: Two Star & The Dream Police Clairo: Charm Sabrina Carpenter: Short n' Sweet Waxahatchee: Tigers Blood Beyoncé: COWBOY CARTER Billie Eilish: HIT ME HARD AND SOFT |
| 28 | Clairo: Charm | 10 Billie Eilish: HIT ME HARD AND SOFT Mk.gee: Two Star & The Dream Police St. Vincent: All Born Screaming MJ Lenderman: Manning Fireworks Vampire Weekend: Only God Was Above Us Tyler, The Creator: CHROMAKOPIA Magdalena Bay: Imaginal Disk Adrianne Lenker: Bright Future Fontaines D.C.: Romance Sabrina Carpenter: Short n' Sweet |
| 29 | Clarissa Connelly: World of Work | 2 Kim Gordon: The Collective Nala Sinephro: Endlessness |
| 30 | Common & Pete Rock: The Auditorium Vol. 1 | 6 Vince Staples: Dark Times Brittany Howard: What Now ScHoolboy Q: BLUE LIPS The Cure: Songs of a Lost World Adrianne Lenker: Bright Future Jessica Pratt: Here in the Pitch |
| 31 | Confidence Man: 3AM (LA LA LA) | 5 The Last Dinner Party: Prelude to Ecstasy English Teacher: This Could Be Texas Billie Eilish: HIT ME HARD AND SOFT Beyoncé: COWBOY CARTER Fontaines D.C.: Romance |
| 32 | The Cure: Songs of a Lost World | 10 Fontaines D.C.: Romance MJ Lenderman: Manning Fireworks Vampire Weekend: Only God Was Above Us Waxahatchee: Tigers Blood The Last Dinner Party: Prelude to Ecstasy Jessica Pratt: Here in the Pitch Adrianne Lenker: Bright Future Jack White: No Name Nick Cave & The Bad Seeds: Wild God Mannequin Pussy: I Got Heaven |
| 33 | Denzel Curry: King of the Mischievous South Vol. 2 | 2 Beyoncé: COWBOY CARTER Tyler, The Creator: CHROMAKOPIA |
| 34 | DIIV: Frog in Boiling Water | 10 Father John Misty: Mahashmashana Vampire Weekend: Only God Was Above Us Mannequin Pussy: I Got Heaven The Cure: Songs of a Lost World Fontaines D.C.: Romance Mk.gee: Two Star & The Dream Police Adrianne Lenker: Bright Future Clairo: Charm Jessica Pratt: Here in the Pitch Sabrina Carpenter: Short n' Sweet |
| 35 | Doechii: Alligator Bites Never Heal | 10 ScHoolboy Q: BLUE LIPS Kendrick Lamar: GNX Beyoncé: COWBOY CARTER Billie Eilish: HIT ME HARD AND SOFT Sabrina Carpenter: Short n' Sweet Kali Uchis: ORQUÍDEAS Tyler, The Creator: CHROMAKOPIA GloRilla: GLORIOUS MJ Lenderman: Manning Fireworks Mk.gee: Two Star & The Dream Police |
| 36 | Dua Lipa: Radical Optimism | 10 St. Vincent: All Born Screaming Ariana Grande: eternal sunshine Billie Eilish: HIT ME HARD AND SOFT Sabrina Carpenter: Short n' Sweet Beyoncé: COWBOY CARTER Mannequin Pussy: I Got Heaven Vampire Weekend: Only God Was Above Us Clairo: Charm The Last Dinner Party: Prelude to Ecstasy MJ Lenderman: Manning Fireworks |
| 37 | E L U C I D: REVELATOR | 10 Mdou Moctar: Funeral for Justice Nala Sinephro: Endlessness Arooj Aftab: Night Reign Brittany Howard: What Now Tyler, The Creator: CHROMAKOPIA Beth Gibbons: Lives Outgrown Blood Incantation: Absolute Elsewhere ScHoolboy Q: BLUE LIPS Jessica Pratt: Here in the Pitch Doechii: Alligator Bites Never Heal |
| 38 | Ekko Astral: pink balloons | 10 Knocked Loose: You Won't Go Before You're Supposed To Kali Uchis: ORQUÍDEAS Mk.gee: Two Star & The Dream Police ScHoolboy Q: BLUE LIPS Tyler, The Creator: CHROMAKOPIA Fontaines D.C.: Romance Doechii: Alligator Bites Never Heal Mannequin Pussy: I Got Heaven The Cure: Songs of a Lost World Jessica Pratt: Here in the Pitch |
| 39 | Empress Of: For Your Consideration | 10 Arooj Aftab: Night Reign Clairo: Charm Kali Uchis: ORQUÍDEAS Jack White: No Name Beyoncé: COWBOY CARTER Billie Eilish: HIT ME HARD AND SOFT Kim Gordon: The Collective Waxahatchee: Tigers Blood Vampire Weekend: Only God Was Above Us Jessica Pratt: Here in the Pitch |
| 40 | English Teacher: This Could Be Texas | 10 SPRINTS: Letter To Self The Last Dinner Party: Prelude to Ecstasy Amyl and The Sniffers: Cartoon Darkness Fontaines D.C.: Romance The Cure: Songs of a Lost World Wunderhorse: Midas Magdalena Bay: Imaginal Disk Laura Marling: Patterns in Repeat Rachel Chinouriri: What A Devastating Turn of Events Waxahatchee: Tigers Blood |
| 41 | Erika de Casier: Still | 3 Nilüfer Yanya: My Method Actor Mk.gee: Two Star & The Dream Police MJ Lenderman: Manning Fireworks |
| 42 | Ezra Collective: Dance, No One's Watching | 5 Jamie xx: In Waves MJ Lenderman: Manning Fireworks The Cure: Songs of a Lost World Jessica Pratt: Here in the Pitch Fontaines D.C.: Romance |
| 43 | Fabiana Palladino: Fabiana Palladino | 10 Tyla: TYLA Nala Sinephro: Endlessness MJ Lenderman: Manning Fireworks Jessica Pratt: Here in the Pitch Kim Gordon: The Collective Nick Cave & The Bad Seeds: Wild God Jamie xx: In Waves Fontaines D.C.: Romance Mdou Moctar: Funeral for Justice Waxahatchee: Tigers Blood |
| 44 | Fat Dog: WOOF. | 2 The Last Dinner Party: Prelude to Ecstasy St. Vincent: All Born Screaming |
| 45 | Father John Misty: Mahashmashana | 10 MJ Lenderman: Manning Fireworks Vampire Weekend: Only God Was Above Us Wild Pink: Dulling The Horns The Cure: Songs of a Lost World DIIV: Frog in Boiling Water Gouge Away: Deep Sage Fontaines D.C.: Romance Mannequin Pussy: I Got Heaven Cindy Lee: Diamond Jubilee Kendrick Lamar: GNX |
| 46 | Faye Webster: Underdressed at the Symphony | 2 Clairo: Charm Billie Eilish: HIT ME HARD AND SOFT |
| 47 | Fievel Is Glauque: Rong Weicknes | Kim Gordon: The Collective |
| 48 | Floating Points: Cascade | 10 Adrianne Lenker: Bright Future Julia Holter: Something in the Room She Moves Mannequin Pussy: I Got Heaven Mount Eerie: Night Palace Jessica Pratt: Here in the Pitch Blood Incantation: Absolute Elsewhere The Last Dinner Party: Prelude to Ecstasy Arooj Aftab: Night Reign Brittany Howard: What Now Johnny Blue Skies: Passage du Desir |
| 49 | Fontaines D.C.: Romance | 10 The Cure: Songs of a Lost World The Last Dinner Party: Prelude to Ecstasy English Teacher: This Could Be Texas Mannequin Pussy: I Got Heaven Vampire Weekend: Only God Was Above Us MJ Lenderman: Manning Fireworks Tyler, The Creator: CHROMAKOPIA Adrianne Lenker: Bright Future Nick Cave & The Bad Seeds: Wild God Amyl and The Sniffers: Cartoon Darkness |
| 50 | Foxing: Foxing | 5 Chat Pile: Cool World Knocked Loose: You Won't Go Before You're Supposed To Kendrick Lamar: GNX MJ Lenderman: Manning Fireworks The Cure: Songs of a Lost World |
| 51 | Friko: Where we've been, Where we go from here | 4 Cindy Lee: Diamond Jubilee Jessica Pratt: Here in the Pitch Waxahatchee: Tigers Blood MJ Lenderman: Manning Fireworks |
| 52 | Future & Metro Boomin: WE DON'T TRUST YOU | 9 Future & Metro Boomin: WE STILL DON'T TRUST YOU Vince Staples: Dark Times ScHoolboy Q: BLUE LIPS Doechii: Alligator Bites Never Heal Mk.gee: Two Star & The Dream Police Sabrina Carpenter: Short n' Sweet Tyler, The Creator: CHROMAKOPIA Kendrick Lamar: GNX Beyoncé: COWBOY CARTER |
| 53 | Future & Metro Boomin: WE STILL DON'T TRUST YOU | 6 Future & Metro Boomin: WE DON'T TRUST YOU Doechii: Alligator Bites Never Heal ScHoolboy Q: BLUE LIPS Tyler, The Creator: CHROMAKOPIA Kendrick Lamar: GNX Mk.gee: Two Star & The Dream Police |
| 54 | Gatecreeper: Dark Superstition | Blood Incantation: Absolute Elsewhere |
| 55 | Geordie Greep: The New Sound | 10 Chelsea Wolfe: She Reaches Out to She Reaches Out to She JPEGMAFIA: I LAY DOWN MY LIFE FOR YOU Julia Holter: Something in the Room She Moves Blood Incantation: Absolute Elsewhere Waxahatchee: Tigers Blood Magdalena Bay: Imaginal Disk Brittany Howard: What Now Mount Eerie: Night Palace Kim Gordon: The Collective Beth Gibbons: Lives Outgrown |
| 56 | Gillian Welch & David Rawlings: Woodland | 10 Waxahatchee: Tigers Blood Hurray for the Riff Raff: The Past Is Still Alive Beth Gibbons: Lives Outgrown The Cure: Songs of a Lost World Brittany Howard: What Now Mannequin Pussy: I Got Heaven MJ Lenderman: Manning Fireworks Nilüfer Yanya: My Method Actor Vampire Weekend: Only God Was Above Us Jessica Pratt: Here in the Pitch |
| 57 | GloRilla: GLORIOUS | 10 BigXthaPlug: TAKE CARE ScHoolboy Q: BLUE LIPS Doechii: Alligator Bites Never Heal Tyla: TYLA Tyler, The Creator: CHROMAKOPIA Kendrick Lamar: GNX Mk.gee: Two Star & The Dream Police Sabrina Carpenter: Short n' Sweet Beyoncé: COWBOY CARTER Billie Eilish: HIT ME HARD AND SOFT |
| 58 | Godspeed You! Black Emperor: “NO TITLE AS OF 13 FEBRUARY 2024 28,340 DEAD” | 10 Cindy Lee: Diamond Jubilee Magdalena Bay: Imaginal Disk Kim Gordon: The Collective Vince Staples: Dark Times English Teacher: This Could Be Texas Mannequin Pussy: I Got Heaven Adrianne Lenker: Bright Future Mount Eerie: Night Palace The Last Dinner Party: Prelude to Ecstasy Jack White: No Name |
| 59 | Gouge Away: Deep Sage | 10 High Vis: Guided Tour Chat Pile: Cool World Father John Misty: Mahashmashana Mannequin Pussy: I Got Heaven Blood Incantation: Absolute Elsewhere The Cure: Songs of a Lost World Nilüfer Yanya: My Method Actor Tyler, The Creator: CHROMAKOPIA MJ Lenderman: Manning Fireworks Jessica Pratt: Here in the Pitch |
| 60 | Gracie Abrams: The Secret of Us | 5 Kacey Musgraves: Deeper Well Sabrina Carpenter: Short n' Sweet St. Vincent: All Born Screaming Billie Eilish: HIT ME HARD AND SOFT Beyoncé: COWBOY CARTER |
| 61 | Green Day: Saviors | The Cure: Songs of a Lost World |
| 62 | Hamish Hawk: A Firmer Hand | 2 Amyl and The Sniffers: Cartoon Darkness Jessica Pratt: Here in the Pitch |
| 63 | The Hard Quartet: The Hard Quartet | 4 MJ Lenderman: Manning Fireworks The Cure: Songs of a Lost World Waxahatchee: Tigers Blood Jessica Pratt: Here in the Pitch |
| 64 | High Vis: Guided Tour | 4 Gouge Away: Deep Sage Mannequin Pussy: I Got Heaven Fontaines D.C.: Romance The Cure: Songs of a Lost World |
| 65 | Hovvdy: Hovvdy | 10 Doechii: Alligator Bites Never Heal Magdalena Bay: Imaginal Disk Father John Misty: Mahashmashana Vampire Weekend: Only God Was Above Us Nilüfer Yanya: My Method Actor MJ Lenderman: Manning Fireworks Mk.gee: Two Star & The Dream Police Mannequin Pussy: I Got Heaven Sabrina Carpenter: Short n' Sweet Beyoncé: COWBOY CARTER |
| 66 | Hurray for the Riff Raff: The Past Is Still Alive | 10 Mount Eerie: Night Palace MJ Lenderman: Manning Fireworks Beyoncé: COWBOY CARTER Gillian Welch & David Rawlings: Woodland KA: The Thief Next to Jesus Waxahatchee: Tigers Blood Mannequin Pussy: I Got Heaven Kali Uchis: ORQUÍDEAS Mdou Moctar: Funeral for Justice Jessica Pratt: Here in the Pitch |
| 67 | IDLES: TANGK | 10 Amyl and The Sniffers: Cartoon Darkness The Cure: Songs of a Lost World SPRINTS: Letter To Self The Last Dinner Party: Prelude to Ecstasy Fontaines D.C.: Romance Tyler, The Creator: CHROMAKOPIA KNEECAP: Fine Art Vampire Weekend: Only God Was Above Us Beth Gibbons: Lives Outgrown English Teacher: This Could Be Texas |
| 68 | Jack White: No Name | 10 The Cure: Songs of a Lost World Vampire Weekend: Only God Was Above Us Beyoncé: COWBOY CARTER Kendrick Lamar: GNX Tyler, The Creator: CHROMAKOPIA Waxahatchee: Tigers Blood Billie Eilish: HIT ME HARD AND SOFT Adrianne Lenker: Bright Future Jamie xx: In Waves Fontaines D.C.: Romance |
| 69 | Jamie xx: In Waves | 10 Fontaines D.C.: Romance Justice: Hyperdrama Jack White: No Name The Cure: Songs of a Lost World Tyler, The Creator: CHROMAKOPIA Nick Cave & The Bad Seeds: Wild God Jessica Pratt: Here in the Pitch Beyoncé: COWBOY CARTER Yard Act: Where's My Utopia? MJ Lenderman: Manning Fireworks |
| 70 | Jessica Pratt: Here in the Pitch | 10 MJ Lenderman: Manning Fireworks The Cure: Songs of a Lost World Cindy Lee: Diamond Jubilee Waxahatchee: Tigers Blood Arooj Aftab: Night Reign Mdou Moctar: Funeral for Justice Beth Gibbons: Lives Outgrown Mannequin Pussy: I Got Heaven Kim Gordon: The Collective Doechii: Alligator Bites Never Heal |
| 71 | Jlin: Akoma | 6 Mabe Fratti: Sentir Que No Sabes Nala Sinephro: Endlessness Arooj Aftab: Night Reign Kim Gordon: The Collective Nilüfer Yanya: My Method Actor MJ Lenderman: Manning Fireworks |
| 72 | Johnny Blue Skies: Passage du Desir | 10 The Cure: Songs of a Lost World MJ Lenderman: Manning Fireworks Waxahatchee: Tigers Blood Jessica Pratt: Here in the Pitch Blood Incantation: Absolute Elsewhere Brittany Howard: What Now Adrianne Lenker: Bright Future Jack White: No Name Nilüfer Yanya: My Method Actor Mannequin Pussy: I Got Heaven |
| 73 | JPEGMAFIA: I LAY DOWN MY LIFE FOR YOU | 10 Geordie Greep: The New Sound Beth Gibbons: Lives Outgrown Kim Gordon: The Collective Blood Incantation: Absolute Elsewhere Kendrick Lamar: GNX Nala Sinephro: Endlessness Waxahatchee: Tigers Blood The Last Dinner Party: Prelude to Ecstasy Vampire Weekend: Only God Was Above Us Jessica Pratt: Here in the Pitch |
| 74 | Judas Priest: Invincible Shield | Blood Incantation: Absolute Elsewhere |
| 75 | Julia Holter: Something in the Room She Moves | 10 Adrianne Lenker: Bright Future Beth Gibbons: Lives Outgrown Arooj Aftab: Night Reign Chelsea Wolfe: She Reaches Out to She Reaches Out to She Floating Points: Cascade Geordie Greep: The New Sound Mount Eerie: Night Palace Blood Incantation: Absolute Elsewhere Kim Gordon: The Collective The Cure: Songs of a Lost World |
| 76 | Justice: Hyperdrama | 3 Jamie xx: In Waves Fontaines D.C.: Romance The Cure: Songs of a Lost World |
| 77 | KA: The Thief Next to Jesus | 10 Mach-Hommy: #RICHAXXHAITIAN Mannequin Pussy: I Got Heaven Mount Eerie: Night Palace LL COOL J: THE FORCE Cindy Lee: Diamond Jubilee Hurray for the Riff Raff: The Past Is Still Alive Kim Gordon: The Collective MJ Lenderman: Manning Fireworks Tyler, The Creator: CHROMAKOPIA Blood Incantation: Absolute Elsewhere |
| 78 | Kacey Musgraves: Deeper Well | 10 Sabrina Carpenter: Short n' Sweet Gracie Abrams: The Secret of Us Billie Eilish: HIT ME HARD AND SOFT Ariana Grande: eternal sunshine Beyoncé: COWBOY CARTER Taylor Swift: THE TORTURED POETS DEPARTMENT Kendrick Lamar: GNX Jack White: No Name Doechii: Alligator Bites Never Heal The Cure: Songs of a Lost World |
| 79 | Kali Uchis: ORQUÍDEAS | 10 Doechii: Alligator Bites Never Heal ScHoolboy Q: BLUE LIPS Billie Eilish: HIT ME HARD AND SOFT Beyoncé: COWBOY CARTER Tyla: TYLA Vampire Weekend: Only God Was Above Us Clairo: Charm Ekko Astral: pink balloons Empress Of: For Your Consideration Sabrina Carpenter: Short n' Sweet |
| 80 | Kamasi Washington: Fearless Movement | 4 Vampire Weekend: Only God Was Above Us The Cure: Songs of a Lost World Adrianne Lenker: Bright Future Billie Eilish: HIT ME HARD AND SOFT |
| 81 | KAYTRANADA: Timeless | 3 Sabrina Carpenter: Short n' Sweet Beyoncé: COWBOY CARTER The Cure: Songs of a Lost World |
| 82 | Kelly Lee Owens: Dreamstate | 10 Nia Archives: Silence Is Loud SPRINTS: Letter To Self Tyla: TYLA English Teacher: This Could Be Texas Clairo: Charm Waxahatchee: Tigers Blood Magdalena Bay: Imaginal Disk Vampire Weekend: Only God Was Above Us Sabrina Carpenter: Short n' Sweet Fontaines D.C.: Romance |
| 83 | Kendrick Lamar: GNX | 10 Doechii: Alligator Bites Never Heal Beyoncé: COWBOY CARTER Billie Eilish: HIT ME HARD AND SOFT ScHoolboy Q: BLUE LIPS Jack White: No Name MJ Lenderman: Manning Fireworks Tyler, The Creator: CHROMAKOPIA The Cure: Songs of a Lost World Vince Staples: Dark Times Sabrina Carpenter: Short n' Sweet |
| 84 | Kim Deal: Nobody Loves You More | 10 The Cure: Songs of a Lost World Nick Cave & The Bad Seeds: Wild God English Teacher: This Could Be Texas Mannequin Pussy: I Got Heaven Billie Eilish: HIT ME HARD AND SOFT The Last Dinner Party: Prelude to Ecstasy Beyoncé: COWBOY CARTER Fontaines D.C.: Romance MJ Lenderman: Manning Fireworks Adrianne Lenker: Bright Future |
| 85 | Kim Gordon: The Collective | 10 Waxahatchee: Tigers Blood Mount Eerie: Night Palace Adrianne Lenker: Bright Future MJ Lenderman: Manning Fireworks Jessica Pratt: Here in the Pitch Nala Sinephro: Endlessness Magdalena Bay: Imaginal Disk Cindy Lee: Diamond Jubilee Mannequin Pussy: I Got Heaven Nilüfer Yanya: My Method Actor |
| 86 | KNEECAP: Fine Art | 10 Fontaines D.C.: Romance The Last Dinner Party: Prelude to Ecstasy Adrianne Lenker: Bright Future Amyl and The Sniffers: Cartoon Darkness IDLES: TANGK English Teacher: This Could Be Texas St. Vincent: All Born Screaming Knocked Loose: You Won't Go Before You're Supposed To Tyler, The Creator: CHROMAKOPIA Clairo: Charm |
| 87 | Knocked Loose: You Won't Go Before You're Supposed To | 10 Chat Pile: Cool World Bring Me The Horizon: POST HUMAN: NeX GEn Chelsea Wolfe: She Reaches Out to She Reaches Out to She Blood Incantation: Absolute Elsewhere Lip Critic: Hex Dealer Touché Amoré: Spiral in a Straight Line Foxing: Foxing Zach Bryan: The Great American Bar Scene Magdalena Bay: Imaginal Disk The Cure: Songs of a Lost World |
| 88 | The Last Dinner Party: Prelude to Ecstasy | 10 English Teacher: This Could Be Texas St. Vincent: All Born Screaming Fontaines D.C.: Romance Adrianne Lenker: Bright Future The Cure: Songs of a Lost World Rachel Chinouriri: What A Devastating Turn of Events Vampire Weekend: Only God Was Above Us Amyl and The Sniffers: Cartoon Darkness Wunderhorse: Midas Laura Marling: Patterns in Repeat |
| 89 | Laura Marling: Patterns in Repeat | 10 The Last Dinner Party: Prelude to Ecstasy Vampire Weekend: Only God Was Above Us English Teacher: This Could Be Texas Kim Gordon: The Collective Los Campesinos!: All Hell Nadine Shah: Filthy Underneath Adrianne Lenker: Bright Future Magdalena Bay: Imaginal Disk SPRINTS: Letter To Self The Cure: Songs of a Lost World |
| 90 | The Lemon Twigs: A Dream Is All We Know | 2 Beth Gibbons: Lives Outgrown Kim Gordon: The Collective |
| 91 | Lime Garden: One More Thing | 2 English Teacher: This Could Be Texas The Last Dinner Party: Prelude to Ecstasy |
| 92 | Lip Critic: Hex Dealer | 3 Knocked Loose: You Won't Go Before You're Supposed To Mannequin Pussy: I Got Heaven Fontaines D.C.: Romance |
| 93 | Liquid Mike: Paul Bunyan's Slingshot | 2 Waxahatchee: Tigers Blood MJ Lenderman: Manning Fireworks |
| 94 | LL COOL J: THE FORCE | 6 Mach-Hommy: #RICHAXXHAITIAN KA: The Thief Next to Jesus Kendrick Lamar: GNX Doechii: Alligator Bites Never Heal Mk.gee: Two Star & The Dream Police Tyler, The Creator: CHROMAKOPIA |
| 95 | Los Campesinos!: All Hell | 10 Laura Marling: Patterns in Repeat Arooj Aftab: Night Reign English Teacher: This Could Be Texas The Cure: Songs of a Lost World Nala Sinephro: Endlessness Nilüfer Yanya: My Method Actor Fontaines D.C.: Romance Magdalena Bay: Imaginal Disk Vampire Weekend: Only God Was Above Us Cindy Lee: Diamond Jubilee |
| 96 | Mabe Fratti: Sentir Que No Sabes | 10 Nala Sinephro: Endlessness Jlin: Akoma Cassandra Jenkins: My Light, My Destroyer Arooj Aftab: Night Reign MJ Lenderman: Manning Fireworks Jessica Pratt: Here in the Pitch Kim Gordon: The Collective Nilüfer Yanya: My Method Actor Chat Pile: Cool World Cindy Lee: Diamond Jubilee |
| 97 | Mach-Hommy: #RICHAXXHAITIAN | 10 KA: The Thief Next to Jesus LL COOL J: THE FORCE Cindy Lee: Diamond Jubilee ScHoolboy Q: BLUE LIPS Doechii: Alligator Bites Never Heal Chat Pile: Cool World Tyler, The Creator: CHROMAKOPIA Kendrick Lamar: GNX Blood Incantation: Absolute Elsewhere Mk.gee: Two Star & The Dream Police |
| 98 | Magdalena Bay: Imaginal Disk | 10 Cindy Lee: Diamond Jubilee Mannequin Pussy: I Got Heaven Vampire Weekend: Only God Was Above Us Adrianne Lenker: Bright Future Waxahatchee: Tigers Blood MJ Lenderman: Manning Fireworks Vince Staples: Dark Times Kim Gordon: The Collective English Teacher: This Could Be Texas Chat Pile: Cool World |
| 99 | Maggie Rogers: Don't Forget Me | 10 Vince Staples: Dark Times A. G. Cook: Britpop Billie Eilish: HIT ME HARD AND SOFT Jack White: No Name ScHoolboy Q: BLUE LIPS Taylor Swift: THE TORTURED POETS DEPARTMENT Kendrick Lamar: GNX Clairo: Charm Ariana Grande: eternal sunshine Kali Uchis: ORQUÍDEAS |
| 100 | Mannequin Pussy: I Got Heaven | 10 MJ Lenderman: Manning Fireworks Waxahatchee: Tigers Blood The Cure: Songs of a Lost World Fontaines D.C.: Romance Blood Incantation: Absolute Elsewhere Magdalena Bay: Imaginal Disk Mount Eerie: Night Palace Jessica Pratt: Here in the Pitch Vampire Weekend: Only God Was Above Us Cindy Lee: Diamond Jubilee |
| 101 | The Marías: Submarine | 4 Clairo: Charm The Last Dinner Party: Prelude to Ecstasy Billie Eilish: HIT ME HARD AND SOFT Tyler, The Creator: CHROMAKOPIA |
| 102 | Mdou Moctar: Funeral for Justice | 10 MJ Lenderman: Manning Fireworks Jessica Pratt: Here in the Pitch MIKE & Tony Seltzer: Pinball Cindy Lee: Diamond Jubilee Arooj Aftab: Night Reign E L U C I D: REVELATOR Waxahatchee: Tigers Blood Jack White: No Name The Cure: Songs of a Lost World Kim Gordon: The Collective |
| 103 | Michael Kiwanuka: Small Changes | 3 Amyl and The Sniffers: Cartoon Darkness The Cure: Songs of a Lost World The Last Dinner Party: Prelude to Ecstasy |
| 104 | MIKE & Tony Seltzer: Pinball | 4 Mdou Moctar: Funeral for Justice Magdalena Bay: Imaginal Disk Cindy Lee: Diamond Jubilee The Cure: Songs of a Lost World |
| 105 | MJ Lenderman: Manning Fireworks | 10 Waxahatchee: Tigers Blood Jessica Pratt: Here in the Pitch Mannequin Pussy: I Got Heaven The Cure: Songs of a Lost World Father John Misty: Mahashmashana Cindy Lee: Diamond Jubilee Fontaines D.C.: Romance Mdou Moctar: Funeral for Justice Mk.gee: Two Star & The Dream Police Nilüfer Yanya: My Method Actor |
| 106 | Mk.gee: Two Star & The Dream Police | 10 MJ Lenderman: Manning Fireworks Clairo: Charm Tyler, The Creator: CHROMAKOPIA Doechii: Alligator Bites Never Heal Fontaines D.C.: Romance Cindy Lee: Diamond Jubilee Billie Eilish: HIT ME HARD AND SOFT Nilüfer Yanya: My Method Actor Waxahatchee: Tigers Blood Tems: Born in the Wild |
| 107 | Mount Eerie: Night Palace | 10 Kim Gordon: The Collective Hurray for the Riff Raff: The Past Is Still Alive Mannequin Pussy: I Got Heaven Bladee: Cold Visions Cindy Lee: Diamond Jubilee Chat Pile: Cool World KA: The Thief Next to Jesus Magdalena Bay: Imaginal Disk Arooj Aftab: Night Reign Floating Points: Cascade |
| 108 | Mustafa: Dunya | 10 Tyler, The Creator: CHROMAKOPIA Mk.gee: Two Star & The Dream Police ScHoolboy Q: BLUE LIPS Nilüfer Yanya: My Method Actor Kendrick Lamar: GNX Doechii: Alligator Bites Never Heal MJ Lenderman: Manning Fireworks Waxahatchee: Tigers Blood Fontaines D.C.: Romance The Cure: Songs of a Lost World |
| 109 | Nadine Shah: Filthy Underneath | 10 The Last Dinner Party: Prelude to Ecstasy Laura Marling: Patterns in Repeat Amyl and The Sniffers: Cartoon Darkness Kim Gordon: The Collective English Teacher: This Could Be Texas St. Vincent: All Born Screaming Adrianne Lenker: Bright Future Jessica Pratt: Here in the Pitch Waxahatchee: Tigers Blood Vampire Weekend: Only God Was Above Us |
| 110 | Nala Sinephro: Endlessness | 10 Mabe Fratti: Sentir Que No Sabes Kim Gordon: The Collective Arooj Aftab: Night Reign Cassandra Jenkins: My Light, My Destroyer Still House Plants: If I don't make it, I love u E L U C I D: REVELATOR Jlin: Akoma MJ Lenderman: Manning Fireworks Waxahatchee: Tigers Blood Chanel Beads: Your Day Will Come |
| 111 | Nia Archives: Silence Is Loud | 10 Kelly Lee Owens: Dreamstate Rachel Chinouriri: What A Devastating Turn of Events Tyla: TYLA The Last Dinner Party: Prelude to Ecstasy Amyl and The Sniffers: Cartoon Darkness SPRINTS: Letter To Self English Teacher: This Could Be Texas Doechii: Alligator Bites Never Heal Kali Uchis: ORQUÍDEAS Nala Sinephro: Endlessness |
| 112 | Nick Cave & The Bad Seeds: Wild God | 10 The Cure: Songs of a Lost World Fontaines D.C.: Romance St. Vincent: All Born Screaming Vampire Weekend: Only God Was Above Us Billie Eilish: HIT ME HARD AND SOFT The Last Dinner Party: Prelude to Ecstasy Adrianne Lenker: Bright Future Jamie xx: In Waves Kim Deal: Nobody Loves You More Jack White: No Name |
| 113 | Nilüfer Yanya: My Method Actor | 10 MJ Lenderman: Manning Fireworks The Cure: Songs of a Lost World Waxahatchee: Tigers Blood Arooj Aftab: Night Reign Magdalena Bay: Imaginal Disk Cassandra Jenkins: My Light, My Destroyer Kim Gordon: The Collective Blood Incantation: Absolute Elsewhere Tyler, The Creator: CHROMAKOPIA Mannequin Pussy: I Got Heaven |
| 114 | Nubya Garcia: ODYSSEY | The Cure: Songs of a Lost World |
| 115 | NxWorries: WHY LAWD? | 8 Vince Staples: Dark Times ScHoolboy Q: BLUE LIPS Doechii: Alligator Bites Never Heal Tyler, The Creator: CHROMAKOPIA Vampire Weekend: Only God Was Above Us Beyoncé: COWBOY CARTER Kendrick Lamar: GNX Billie Eilish: HIT ME HARD AND SOFT |
| 116 | Opeth: The Last Will and Testament | Blood Incantation: Absolute Elsewhere |
| 117 | Pet Shop Boys: Nonetheless | 2 Waxahatchee: Tigers Blood The Cure: Songs of a Lost World |
| 118 | Rachel Chinouriri: What A Devastating Turn of Events | 10 The Last Dinner Party: Prelude to Ecstasy Nia Archives: Silence Is Loud Wunderhorse: Midas English Teacher: This Could Be Texas Billie Eilish: HIT ME HARD AND SOFT Amyl and The Sniffers: Cartoon Darkness SPRINTS: Letter To Self Fontaines D.C.: Romance The Cure: Songs of a Lost World Clairo: Charm |
| 119 | Ravyn Lenae: Bird's Eye | 2 Doechii: Alligator Bites Never Heal Mannequin Pussy: I Got Heaven |
| 120 | Rema: HEIS | 10 Tems: Born in the Wild Tyla: TYLA Mk.gee: Two Star & The Dream Police ScHoolboy Q: BLUE LIPS Sabrina Carpenter: Short n' Sweet Waxahatchee: Tigers Blood Beyoncé: COWBOY CARTER Tyler, The Creator: CHROMAKOPIA Kendrick Lamar: GNX MJ Lenderman: Manning Fireworks |
| 121 | Remi Wolf: Big Ideas | 10 St. Vincent: All Born Screaming A. G. Cook: Britpop Nilüfer Yanya: My Method Actor Sabrina Carpenter: Short n' Sweet Doechii: Alligator Bites Never Heal Magdalena Bay: Imaginal Disk Clairo: Charm Billie Eilish: HIT ME HARD AND SOFT Kali Uchis: ORQUÍDEAS Waxahatchee: Tigers Blood |
| 122 | Rosali: Bite Down | 4 Vampire Weekend: Only God Was Above Us Doechii: Alligator Bites Never Heal Billie Eilish: HIT ME HARD AND SOFT The Cure: Songs of a Lost World |
| 123 | Sabrina Carpenter: Short n' Sweet | 10 Billie Eilish: HIT ME HARD AND SOFT Beyoncé: COWBOY CARTER Doechii: Alligator Bites Never Heal Taylor Swift: THE TORTURED POETS DEPARTMENT Ariana Grande: eternal sunshine Kacey Musgraves: Deeper Well MJ Lenderman: Manning Fireworks Tyla: TYLA Kendrick Lamar: GNX Magdalena Bay: Imaginal Disk |
| 124 | ScHoolboy Q: BLUE LIPS | 10 Doechii: Alligator Bites Never Heal Tyler, The Creator: CHROMAKOPIA Vince Staples: Dark Times GloRilla: GLORIOUS Kendrick Lamar: GNX Kali Uchis: ORQUÍDEAS Future & Metro Boomin: WE DON'T TRUST YOU NxWorries: WHY LAWD? The Cure: Songs of a Lost World Beyoncé: COWBOY CARTER |
| 125 | Shabaka: Perceive Its Beauty, Acknowledge Its Grace | Kim Gordon: The Collective |
| 126 | The Smile: Wall of Eyes | 10 The Cure: Songs of a Lost World Fontaines D.C.: Romance The Last Dinner Party: Prelude to Ecstasy Amyl and The Sniffers: Cartoon Darkness English Teacher: This Could Be Texas Tyler, The Creator: CHROMAKOPIA Beth Gibbons: Lives Outgrown Nilüfer Yanya: My Method Actor St. Vincent: All Born Screaming Mannequin Pussy: I Got Heaven |
| 127 | SPRINTS: Letter To Self | 10 English Teacher: This Could Be Texas Amyl and The Sniffers: Cartoon Darkness IDLES: TANGK Wunderhorse: Midas The Last Dinner Party: Prelude to Ecstasy Kelly Lee Owens: Dreamstate Rachel Chinouriri: What A Devastating Turn of Events Nia Archives: Silence Is Loud Laura Marling: Patterns in Repeat Magdalena Bay: Imaginal Disk |
| 128 | St. Vincent: All Born Screaming | 10 The Last Dinner Party: Prelude to Ecstasy Billie Eilish: HIT ME HARD AND SOFT Dua Lipa: Radical Optimism The Cure: Songs of a Lost World Nick Cave & The Bad Seeds: Wild God Clairo: Charm Fontaines D.C.: Romance Vampire Weekend: Only God Was Above Us Adrianne Lenker: Bright Future Waxahatchee: Tigers Blood |
| 129 | Still House Plants: If I don't make it, I love u | 10 Nala Sinephro: Endlessness Kim Gordon: The Collective Kali Uchis: ORQUÍDEAS Arooj Aftab: Night Reign Vampire Weekend: Only God Was Above Us Laura Marling: Patterns in Repeat Nilüfer Yanya: My Method Actor Mannequin Pussy: I Got Heaven Adrianne Lenker: Bright Future Cindy Lee: Diamond Jubilee |
| 130 | Taylor Swift: THE TORTURED POETS DEPARTMENT | 10 Sabrina Carpenter: Short n' Sweet Billie Eilish: HIT ME HARD AND SOFT Beyoncé: COWBOY CARTER The Cure: Songs of a Lost World Maggie Rogers: Don't Forget Me The Last Dinner Party: Prelude to Ecstasy Kacey Musgraves: Deeper Well Vampire Weekend: Only God Was Above Us Ariana Grande: eternal sunshine Rachel Chinouriri: What A Devastating Turn of Events |
| 131 | Tems: Born in the Wild | 10 Rema: HEIS Tyla: TYLA Mk.gee: Two Star & The Dream Police Beyoncé: COWBOY CARTER Sabrina Carpenter: Short n' Sweet Clairo: Charm Billie Eilish: HIT ME HARD AND SOFT Doechii: Alligator Bites Never Heal Tyler, The Creator: CHROMAKOPIA Kendrick Lamar: GNX |
| 132 | This Is Lorelei: Box For Buddy, Box For Star | 10 Wild Pink: Dulling The Horns Being Dead: EELS Mannequin Pussy: I Got Heaven Waxahatchee: Tigers Blood Vampire Weekend: Only God Was Above Us Cindy Lee: Diamond Jubilee MJ Lenderman: Manning Fireworks Nilüfer Yanya: My Method Actor Blood Incantation: Absolute Elsewhere Magdalena Bay: Imaginal Disk |
| 133 | Thou: Umbilical | 4 Chelsea Wolfe: She Reaches Out to She Reaches Out to She Blood Incantation: Absolute Elsewhere ScHoolboy Q: BLUE LIPS The Cure: Songs of a Lost World |
| 134 | Tierra Whack: WORLD WIDE WHACK | 4 Doechii: Alligator Bites Never Heal Sabrina Carpenter: Short n' Sweet Beyoncé: COWBOY CARTER Billie Eilish: HIT ME HARD AND SOFT |
| 135 | Touché Amoré: Spiral in a Straight Line | 10 Chat Pile: Cool World Knocked Loose: You Won't Go Before You're Supposed To Chelsea Wolfe: She Reaches Out to She Reaches Out to She The Cure: Songs of a Lost World Blood Incantation: Absolute Elsewhere Mannequin Pussy: I Got Heaven Beth Gibbons: Lives Outgrown Tyler, The Creator: CHROMAKOPIA Fontaines D.C.: Romance Waxahatchee: Tigers Blood |
| 136 | Tyla: TYLA | 10 Rema: HEIS Tems: Born in the Wild Sabrina Carpenter: Short n' Sweet Kali Uchis: ORQUÍDEAS Fabiana Palladino: Fabiana Palladino Nia Archives: Silence Is Loud Doechii: Alligator Bites Never Heal GloRilla: GLORIOUS ScHoolboy Q: BLUE LIPS Kelly Lee Owens: Dreamstate |
| 137 | Tyler, The Creator: CHROMAKOPIA | 10 ScHoolboy Q: BLUE LIPS Fontaines D.C.: Romance The Cure: Songs of a Lost World Mk.gee: Two Star & The Dream Police Doechii: Alligator Bites Never Heal Waxahatchee: Tigers Blood Adrianne Lenker: Bright Future Cindy Lee: Diamond Jubilee Kendrick Lamar: GNX Jack White: No Name |
| 138 | Vampire Weekend: Only God Was Above Us | 10 Adrianne Lenker: Bright Future The Cure: Songs of a Lost World Fontaines D.C.: Romance The Last Dinner Party: Prelude to Ecstasy Jack White: No Name Magdalena Bay: Imaginal Disk Father John Misty: Mahashmashana Billie Eilish: HIT ME HARD AND SOFT MJ Lenderman: Manning Fireworks Laura Marling: Patterns in Repeat |
| 139 | Vince Staples: Dark Times | 10 ScHoolboy Q: BLUE LIPS Magdalena Bay: Imaginal Disk Common & Pete Rock: The Auditorium Vol. 1 Future & Metro Boomin: WE DON'T TRUST YOU NxWorries: WHY LAWD? Maggie Rogers: Don't Forget Me Kendrick Lamar: GNX Doechii: Alligator Bites Never Heal Jack White: No Name Beyoncé: COWBOY CARTER |
| 140 | Waxahatchee: Tigers Blood | 10 MJ Lenderman: Manning Fireworks The Cure: Songs of a Lost World Mannequin Pussy: I Got Heaven Kim Gordon: The Collective Jessica Pratt: Here in the Pitch Magdalena Bay: Imaginal Disk Adrianne Lenker: Bright Future Cindy Lee: Diamond Jubilee Fontaines D.C.: Romance Vampire Weekend: Only God Was Above Us |
| 141 | Wild Pink: Dulling The Horns | 8 This Is Lorelei: Box For Buddy, Box For Star Father John Misty: Mahashmashana Magdalena Bay: Imaginal Disk Vampire Weekend: Only God Was Above Us MJ Lenderman: Manning Fireworks Mannequin Pussy: I Got Heaven Waxahatchee: Tigers Blood Fontaines D.C.: Romance |
| 142 | Wishy: Triple Seven | 3 Mannequin Pussy: I Got Heaven Fontaines D.C.: Romance MJ Lenderman: Manning Fireworks |
| 143 | Wunderhorse: Midas | 8 The Last Dinner Party: Prelude to Ecstasy English Teacher: This Could Be Texas Rachel Chinouriri: What A Devastating Turn of Events Amyl and The Sniffers: Cartoon Darkness SPRINTS: Letter To Self Fontaines D.C.: Romance The Cure: Songs of a Lost World Billie Eilish: HIT ME HARD AND SOFT |
| 144 | Yard Act: Where's My Utopia? | 8 The Last Dinner Party: Prelude to Ecstasy Jamie xx: In Waves Beth Gibbons: Lives Outgrown Fontaines D.C.: Romance Vampire Weekend: Only God Was Above Us The Cure: Songs of a Lost World Adrianne Lenker: Bright Future MJ Lenderman: Manning Fireworks |
| 145 | Yasmin Williams: Acadia | 2 ScHoolboy Q: BLUE LIPS Vampire Weekend: Only God Was Above Us |
| 146 | Zach Bryan: The Great American Bar Scene | 6 Knocked Loose: You Won't Go Before You're Supposed To Kendrick Lamar: GNX Billie Eilish: HIT ME HARD AND SOFT The Cure: Songs of a Lost World Sabrina Carpenter: Short n' Sweet Beyoncé: COWBOY CARTER |
That's interesting to me. What's interesting to you?
[PS: Oh, here, I put this dataset up in raw interactive form, so you can play with it yourself if you want.]
For anybody interested in the particular subgeekery of language design, I thought of five potential ways to address the Dactal usability issue of
1. Try to embrace the weirdness. This is always my first discipline. Don't be too quick to treat every weirdness as a problem that has to be solved. Some things are weird compared to outside references, but normal in a new system's internal logic. If a weirdness is really a conceptual inconsistency, embracing it will keep feeling awkward no matter how many times you do it. In this case, I think the most persuasive critique is that Dactal tries to keep the human language of queries in the vocabulary of the data, not the system, and the mechanics in punctuation, but "of" is uneasily poised somewhere between the two. You can work out what
2. Use the tools you already have. Dactal already has a way to create additional properties. So if we want to group tracks by artist and then be able to get back to the grouped tracks with "tracks" instead of saying "of", we can just do this:
3. If we're going to explore adding a new feature to grouping to handling this idea directly, we could just move "tracks=of" from a separate annotation (|) operation into the grouping operation:
4. Doing the relabeling with the same syntax in the other order, however, like:
5. I implemented #4, but I do keep coming back to #2 in my mind. It might be generally useful to have a way of renaming existing properties instead of just duplicating them. Or a way of deleting them, for that matter. So I also implemented
.of.of:=where are we?.of
being hard to follow.
1. Try to embrace the weirdness. This is always my first discipline. Don't be too quick to treat every weirdness as a problem that has to be solved. Some things are weird compared to outside references, but normal in a new system's internal logic. If a weirdness is really a conceptual inconsistency, embracing it will keep feeling awkward no matter how many times you do it. In this case, I think the most persuasive critique is that Dactal tries to keep the human language of queries in the vocabulary of the data, not the system, and the mechanics in punctuation, but "of" is uneasily poised somewhere between the two. You can work out what
topsong=(.of:@1.of#(.of.track info.album:album_type=album),(.of.ts):@1.of.track info)
is saying, but it's work. A query language should help humans talk to each other about our goals, not just help humans talk to computers about accomplishing them. Is that second "@1" in the right place? If we want each artist's second song, do we change one of these @1s to @2, or both, or something else? It's hard to tell. Actually, it's impossible to tell from looking at just this part of the query. You have to trace the logic back through the context of the rest of the query (or the data) to figure out where each "of" leaves you. Which also means that changes to the earlier parts of the query are likely to require changing this part, and in ways that also aren't obvious. Past-me knew what each "of" was doing when he wrote this; future-me is already getting prepared to resent past-me for making him rededuce that stuff again later.
2. Use the tools you already have. Dactal already has a way to create additional properties. So if we want to group tracks by artist and then be able to get back to the grouped tracks with "tracks" instead of saying "of", we can just do this:
tracks/artist|tracks=of
and now each group has both "tracks" and "of". This doubles the amount of data, though, and in multi-level logic that can quickly start to become a non-trivial cost.
3. If we're going to explore adding a new feature to grouping to handling this idea directly, we could just move "tracks=of" from a separate annotation (|) operation into the grouping operation:
tracks/artist,tracks=of
but that syntax already has a meaning, which is to group tracks by both artist and "tracks", where "tracks" is calculated by traversing the "of" property of the tracks. Tracks, in this dummy example, don't have an "of" property, but in the actual playlist query we started with, two of the three grouping layers are grouping previous groups, which do have "of"s, which is exactly the thing I'm trying to improve. So that's clearly not the way.
4. Doing the relabeling with the same syntax in the other order, however, like:
tracks/artist,of=tracks
sacrifices strict parallelism but actually fits into the existing model kind of nicely. Because groups have automatic "of" properties, it would already be problematic to use "of" as a grouping key. So this way fits a useful function into a previously unused space in the language. We haven't completely eliminated the system-vocabulary presence of "of", but now each "of" appears only once, in the bookkeeping of creating groups, and all subsequent logic about those groups can stick to the vocabulary of the data. So my original example becomes:topsong=(
.song:@1.songdates
#(.streams.track info.album:album_type=album),
(.streams.ts)
:@1.streams:@1.track info
)
and now not only is it clear exactly what each @1 means (the first is the first song, the second is the first of the re-sorted songdates), but it's easy to notice that we probably want that third @1 to pick the first song's first songdate's first stream, and given that we're sorting songdates entirely by properties from streams, maybe what we should really be doing is actually.song:@1.songdates
#(.streams.track info.album:album_type=album),
(.streams.ts)
:@1.streams:@1.track info
)
topsong=(.songs:@1.songdates.streams#(.track info.album:album_type=album),ts:@1.track info)
and now the query language is doing its real job of helping us think about what we intend to ask.
5. I implemented #4, but I do keep coming back to #2 in my mind. It might be generally useful to have a way of renaming existing properties instead of just duplicating them. Or a way of deleting them, for that matter. So I also implemented
tracks/artist|tracks=-of
for renaming, andtracks/artist|-of
for deleting. This pushes on issues of mutability and persistence that I probably haven't entirely thought through, so it might not be the right design, but trying is a way of finding out.The thing about "background music" is that you don't need special music in order to pay different attention to it. Or maybe you do, but you don't have to need it. The things you love, intently, can be your background. You just have to internalize that love, so that it feels like an integral part of you with which you move and live, not a novel surprise you are colliding with every time it happens. Even an artwork whose meaning cuts opens your heart is also just a surface of colors, or a timespan of sounds. Put your favorite painting on the wall and put a chair under it. Put your favorite songs on and just turn the volume down a little.
There wouldn't be a corrupt economy of aural jello-shot arbitrage if we all insisted on all our art being real.
There wouldn't be a corrupt economy of aural jello-shot arbitrage if we all insisted on all our art being real.
¶ P.S. (and all the other letters) · 9 January 2025 listen/tech
Software ought to be playful. Life ought to be playful, and thus we should want the tools we use to live it to allow or ideally encourage us to play, to improvise and experiment and digress as much as their seriousness allows. For airplane controls or heart-surgery robots the amount of allowable playfulness is probably low, but for most of the things we deal with in software, the software's ability to do arbitrarily frivolous things with an ease proportionate to inconsequentiality is a pretty good gauge of their expressiveness.
Say, for example, you wanted to produce a list of songs you liked last year, but just one song that begins with each letter of the alphabet. "Why?", someone might ask, but I suggest that "how?" is a more interesting question.
Here's how in Curio. Read and do this stuff if you haven't already, then go to the History page, pick playlist, scroll down to the bottom and click "see the query for this". This gives you the query that produces the playlist view, which is like taking apart your toaster to find the part that goes "ding", except that you can still use the toaster normally even though you've also taken it apart.
We're going to change just two things about this query: take out the part that limits it to 100 tracks, and then group the full list of potential tracks by first letter and pick the top track for each letter-group. Here's that playlist query, in red, with the one bit we need to remove crossed out, and the line we need to add in orange.
The new line groups the songs by "letter", which it defines by taking the name of the top song and splitting it into individual characters. The split function is usually used to break up lists at commas, that sort of useful thing, but if we frivolously split on nothing, which translates as ([]) in Dactal, we get a list of individual characters. The :@1 filters this list to just the first letter in it. Then .(.of:@1) says to take each letter group and go to its first track.
Here's what this gives me from my data:
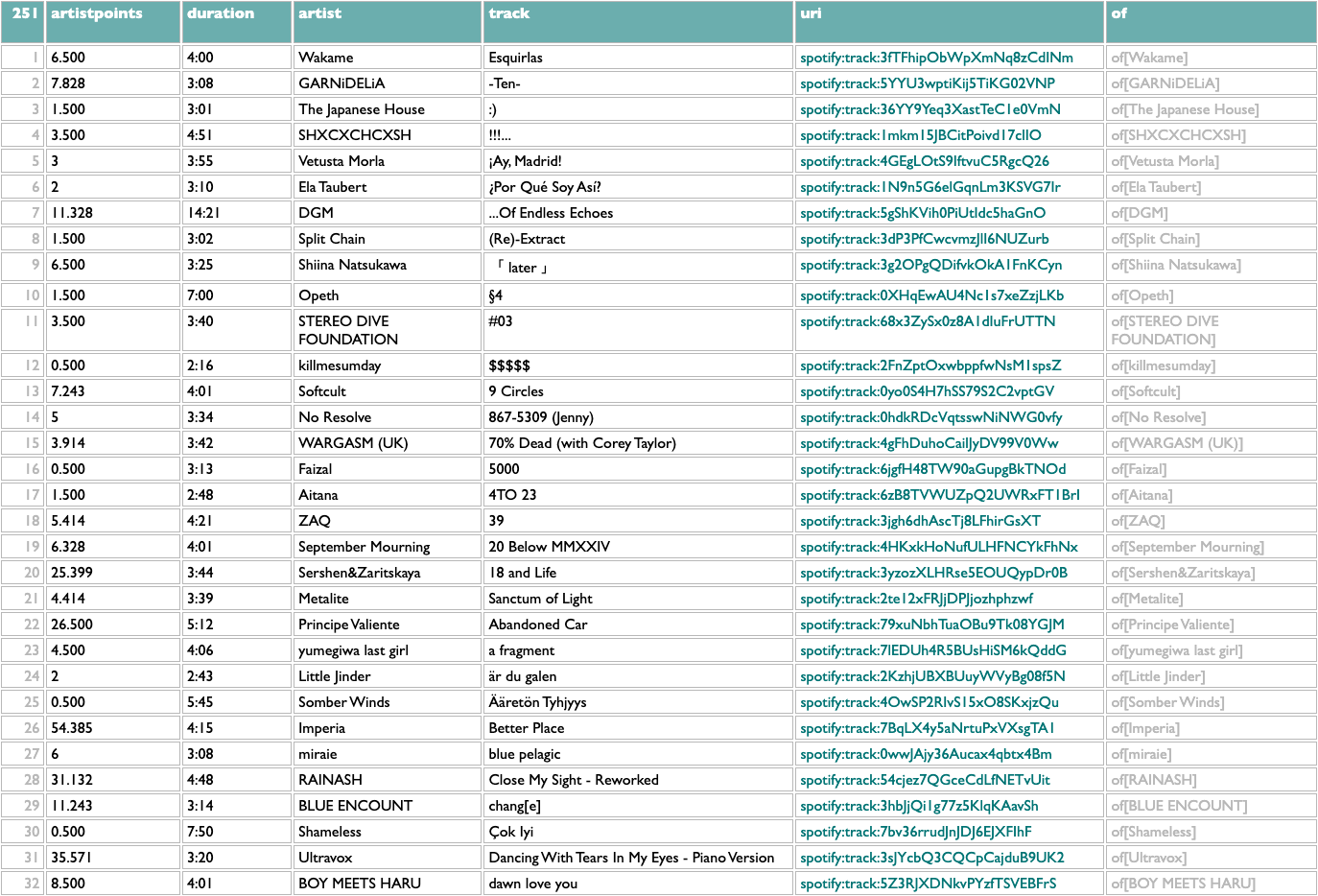
open this weird playlist in Spotify if you want; the premise is non-musical, but the music is still music...
Part of the point of making it easy to experiment is that you never really know what even the seemingly frivolous experiments are going to teach you. We might have thought we were going to get a list of 26 songs out of this, or if we had thought slightly harder we might have realized that we didn't take any steps to avoid songs that begin with punctuation marks, but there are several other maybe-intriguing things we can see here:
- uppercase and lowercase letters are different, obviously, and since song titles are not formally governed by the Chicago Manual of Style Convention, they can have any combination of cases
- accented characters like "Ç" are technically different letters, which will not be news to you if you know almost any language other than English, but maybe you don't
- there are a lot of languages in the world, and you probably do not listen to music in all of them, and neither do I, but still:
- so my obsessive fondness for Japanese kawaii metal and idol rock is most of how I got 251 letters instead of 26
But there are some other curious things here. What's going on with the first song, which seems to be called "Esquirlas", but is at the very top of the list instead of down in alphabetic order with the AaäÄBbCcÇ songs?
Let's find out. Curio is a web app, and the web is like a toolkit for building things that are easy to take apart. The adjustable screwdriver of web apps is the Inspect command. Right-click anything on a web page and pick Inspect.
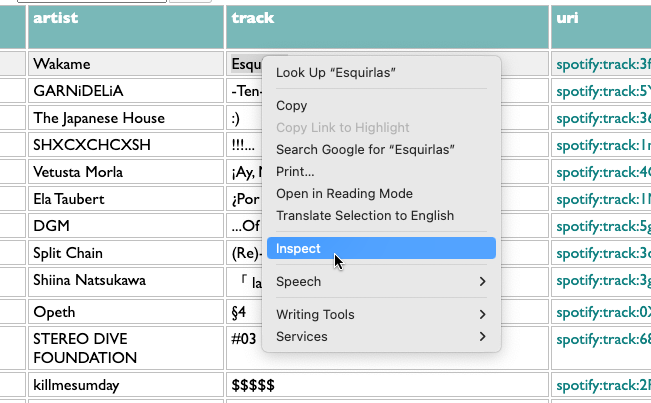
Sometimes you will discover, if you do this, that the people who made the page did not expect you to, and the inside of their page is an incomprehensible mess of wires and crumbs and thus probably a fire hazard. But here's what the inside of this part of the Curio toaster looks like:
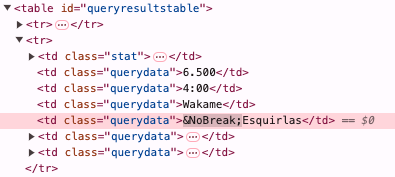
Ah! It looks like this song is called "Esquirlas" when you see it on the page, but in fact in the Spotify database it has a special character at the beginning which somehow comes out of the Spotify API as an (imaginary, I think) HTML entity. We may not think we care about this right now, but later when we're writing song-processing code and we don't understand why
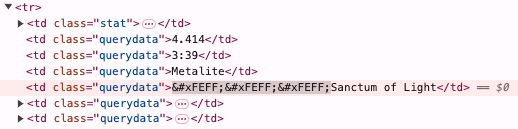
What the hell is
We also learn one interesting thing about the typing I have done with my own weird fingers, because there are songs here beginning with most of the numbers. Not 6, though. There were no songs with titles beginning with the number 6 among my most-played single tracks by each artist. Is that right? We can cross-check.
Yes, apparently I did listen to "6km/h" by CHICKEN BLOW THE IDOL, and "666" by Ceres, but not as much as "rocket pencil" by CHIBLOW (as I assume we fondly refer to them) or "Humming" by Ceres. But the interesting thing I meant we see is that the numbers appear in this list in reverse order. That's my doing, because in my experience I mostly want numbers to be sorted from large to small, and in other query languages I found myself constantly having to sort by the negation of quantities to accomplish this, so I thought Dactal would be more expressive and improvisonational if the default was the other way around. But I didn't remember to handle it differently in the case where we're sorting names that begin with numbers. That's probably fixable. I'll work on fixing my toaster, that's my toaster oath.
What's yours?
[PPS from later:]

[PPPS: Hmm, also, what if we label the "of"s as we group, so that the back-references aren't so meta?]
Say, for example, you wanted to produce a list of songs you liked last year, but just one song that begins with each letter of the alphabet. "Why?", someone might ask, but I suggest that "how?" is a more interesting question.
Here's how in Curio. Read and do this stuff if you haven't already, then go to the History page, pick playlist, scroll down to the bottom and click "see the query for this". This gives you the query that produces the playlist view, which is like taking apart your toaster to find the part that goes "ding", except that you can still use the toaster normally even though you've also taken it apart.
We're going to change just two things about this query: take out the part that limits it to 100 tracks, and then group the full list of potential tracks by first letter and pick the top track for each letter-group. Here's that playlist query, in red, with the one bit we need to remove crossed out, and the line we need to add in orange.
2024 tracks full
/artist=(.track info.artists:@1),song=(.track info.name),date
|songdatepoints=(....count,sqrt)
/artist,song
||songpoints=(..of...songdatepoints,total),
songtime=(..of..of....ms_played,total)
#rank=songpoints,songtime
/artist
|artistpoints=(.of..songpoints..(...._,(0.5),difference)....total),
ms_played=(..of..songtime,total),
topsong=(.of:@1.of#(.of.track info.album:album_type=album),(.of.ts):@1.of.track info)
#artistpoints,ms_played:@<=100
/letter=(.topsong....name,([]),split:@1).(.of:@1)
.(...artistpoints=artistpoints,
duration=(.topsong....duration_ms,mmss),
artist=(.topsong.artists:@1.name),
track=(.topsong.name),
uri=(.topsong.uri))
/artist=(.track info.artists:@1),song=(.track info.name),date
|songdatepoints=(....count,sqrt)
/artist,song
||songpoints=(..of...songdatepoints,total),
songtime=(..of..of....ms_played,total)
#rank=songpoints,songtime
/artist
|artistpoints=(.of..songpoints..(...._,(0.5),difference)....total),
ms_played=(..of..songtime,total),
topsong=(.of:@1.of#(.of.track info.album:album_type=album),(.of.ts):@1.of.track info)
#artistpoints,ms_played:@<=100
/letter=(.topsong....name,([]),split:@1).(.of:@1)
.(...artistpoints=artistpoints,
duration=(.topsong....duration_ms,mmss),
artist=(.topsong.artists:@1.name),
track=(.topsong.name),
uri=(.topsong.uri))
The new line groups the songs by "letter", which it defines by taking the name of the top song and splitting it into individual characters. The split function is usually used to break up lists at commas, that sort of useful thing, but if we frivolously split on nothing, which translates as ([]) in Dactal, we get a list of individual characters. The :@1 filters this list to just the first letter in it. Then .(.of:@1) says to take each letter group and go to its first track.
Here's what this gives me from my data:

open this weird playlist in Spotify if you want; the premise is non-musical, but the music is still music...
Part of the point of making it easy to experiment is that you never really know what even the seemingly frivolous experiments are going to teach you. We might have thought we were going to get a list of 26 songs out of this, or if we had thought slightly harder we might have realized that we didn't take any steps to avoid songs that begin with punctuation marks, but there are several other maybe-intriguing things we can see here:
- uppercase and lowercase letters are different, obviously, and since song titles are not formally governed by the Chicago Manual of Style Convention, they can have any combination of cases
- accented characters like "Ç" are technically different letters, which will not be news to you if you know almost any language other than English, but maybe you don't
- there are a lot of languages in the world, and you probably do not listen to music in all of them, and neither do I, but still:

- so my obsessive fondness for Japanese kawaii metal and idol rock is most of how I got 251 letters instead of 26
But there are some other curious things here. What's going on with the first song, which seems to be called "Esquirlas", but is at the very top of the list instead of down in alphabetic order with the AaäÄBbCcÇ songs?
Let's find out. Curio is a web app, and the web is like a toolkit for building things that are easy to take apart. The adjustable screwdriver of web apps is the Inspect command. Right-click anything on a web page and pick Inspect.
Sometimes you will discover, if you do this, that the people who made the page did not expect you to, and the inside of their page is an incomprehensible mess of wires and crumbs and thus probably a fire hazard. But here's what the inside of this part of the Curio toaster looks like:
Ah! It looks like this song is called "Esquirlas" when you see it on the page, but in fact in the Spotify database it has a special character at the beginning which somehow comes out of the Spotify API as an (imaginary, I think) HTML entity. We may not think we care about this right now, but later when we're writing song-processing code and we don't understand why
songtitle == searchtitle isn't working, suddenly we might think "ohhhh, wait". And you might be tempted to think "nah, that probably won't ever happen again", but in fact it happens again just 20 lines down the page.
What the hell is
? Apparently it is a zero-width non-breaking space from the Unicode group Arabic Presentation Forms-B. What is it doing in the title of a song by the Swedish melodic power metal band Metalite? Apparently we do not know. Welcome to the wonderful world of trying to do anything with music data, or indeed pretty much any data that ever originated in humans typing with their weird fingers, which is essentially all data.
We also learn one interesting thing about the typing I have done with my own weird fingers, because there are songs here beginning with most of the numbers. Not 6, though. There were no songs with titles beginning with the number 6 among my most-played single tracks by each artist. Is that right? We can cross-check.
2024 tracks full:master_metadata_track_name~<6
Yes, apparently I did listen to "6km/h" by CHICKEN BLOW THE IDOL, and "666" by Ceres, but not as much as "rocket pencil" by CHIBLOW (as I assume we fondly refer to them) or "Humming" by Ceres. But the interesting thing I meant we see is that the numbers appear in this list in reverse order. That's my doing, because in my experience I mostly want numbers to be sorted from large to small, and in other query languages I found myself constantly having to sort by the negation of quantities to accomplish this, so I thought Dactal would be more expressive and improvisonational if the default was the other way around. But I didn't remember to handle it differently in the case where we're sorting names that begin with numbers. That's probably fixable. I'll work on fixing my toaster, that's my toaster oath.
What's yours?
[PPS from later:]
[PPPS: Hmm, also, what if we label the "of"s as we group, so that the back-references aren't so meta?]
2024 tracks full
/artist=(.track info.artists:@1),song=(.track info.name),date,of=streams
|songdatepoints=(....count,sqrt)
/artist,song,of=songdates
||songpoints=(..songdates...songdatepoints,total),
songtime=(..songdates..streams....ms_played,total)
#rank=songpoints,songtime
/artist,of=songs
|artistpoints=(..songs..songpoints..(...._,(0.5),difference)....total),
ms_played=(..songs..songtime,total),
topsong=(.songs:@1.songdates
#(.streams.track info.album:album_type=album),(.streams.ts)
:@1.streams:@1.track info)
#artistpoints,ms_played:@<=100
.(...artistpoints=artistpoints,
duration=(.topsong....duration_ms,mmss),
artist=(.topsong.artists:@1.name),
track=(.topsong.name),
uri=(.topsong.uri))
/artist=(.track info.artists:@1),song=(.track info.name),date,of=streams
|songdatepoints=(....count,sqrt)
/artist,song,of=songdates
||songpoints=(..songdates...songdatepoints,total),
songtime=(..songdates..streams....ms_played,total)
#rank=songpoints,songtime
/artist,of=songs
|artistpoints=(..songs..songpoints..(...._,(0.5),difference)....total),
ms_played=(..songs..songtime,total),
topsong=(.songs:@1.songdates
#(.streams.track info.album:album_type=album),(.streams.ts)
:@1.streams:@1.track info)
#artistpoints,ms_played:@<=100
.(...artistpoints=artistpoints,
duration=(.topsong....duration_ms,mmss),
artist=(.topsong.artists:@1.name),
track=(.topsong.name),
uri=(.topsong.uri))
¶ You choose the mood you seek · 8 January 2025 essay/tech
As an editor at a large publisher who liked my proposal for a book but was not going to publish it very reasonably explained to me, commercial publishers are in the business of publishing books that people already know they want to read. In books about music, as other editors told me less apologetically, this mostly means biographies of popular musicians. But glamour does generously leave a little shelf-space for fear, and so the book that a bigger publisher than mine thinks people already want to read is Liz Pelly's Mood Machine: The Rise of Spotify and the Costs of the Perfect Playlist. If you are the people they have in mind, who already wanted to read soberly-researched explanations of some of the ways in which a culture-themed capitalist corporation has pursued capitalism with a disregard for culture, written in a tone of muted resignation, here is your mood. For maximum irony, get the audiobook version and listen to it in the background while you organize your Pinterest boards of Temu products by Pantone color.
As a corporation, Spotify is very normal. Its Swedish origins render it slightly progressive in employment policies relative to American companies, at least if you want to have more children than you already have when you get hired, and can make sure to have them without getting laid off first. In business and product practices, I never saw much reason to consider it better or worse than what one would expect of a medium-to-large-sized publicly-traded tech company.
I arrived at Spotify involuntarily via an acquisition, and left involuntarily via a layoff, but in between those two events I was there voluntarily for a decade. I believe that music is what humans do best, and that bringing all(ish) of the world's music together online is one of the great human cultural achievements of my lifetime, and that the joy-amplifying potential of having the collective love and knowledge encoded in music-listening collated and given back to us is monumental. That's what I spent that decade working on, and although Spotify as a corporation finally voted decisively against this by laying me off and devoting considerable remaining resources to laboriously shutting down everything I worked on, I was hardly the only person working there who believed in music, and wanted there to be a music company that put music above "company", and wanted Spotify to behave in at least a few ways like that company.
It was never very likely to, of course. As Liz begrudgingly notes in her introduction, she set out to write an anti-Spotify book only to realize the problem wasn't really just Spotify so much as power. Spotify entered a music business largely controlled by a few record companies, at a point in history when the other confounding factors in the industry were already technological. Spotify did eventually come up with a few minorly novel forms of moral transgression, but they were never really in a position to explode the existing power structures, even if we could pretend they wanted to.
There were three specific things I fought against throughout my time at Spotify, and although my layoff was officially just part of a large impersonal reduction in "headcount", it's hard to imagine that there wasn't some connection. Mood Machine describes two of these in depressing detail: the secret preferential treatment of particular lower-royalty background music, and the not-secret "marketing" program to pressure artists to voluntarily accept lower royalty rates for the prospect of undisclosed algorithmic promotiom. Liz quotes multiple internal Spotify Slack messages about both these programs, and if somehow this ends up with all those grim private threads getting published, I'll be pleased to get so much of my earnest polemic-writing back. The quote from "yet another employee in the ethics-club" on pages 193-4, pointing out that Discovery Mode is exactly structured to benefit Spotify at the collective expense of artists, is definitely me. I'm pretty sure I went on to explain how to fix the economics of this by making Spotify's benefit conditional on artist benefit, and how to fix the morality of it by actually giving artists interesting agency instead of just an opportunity for submission. Sadly, Liz doesn't quote that part.
But I hadn't resigned in protest over PFC or Discovery Mode, partly because I didn't think either one actually caused sufficient practical damage that removing them would solve enough, but mostly because I had the autonomy and ability to spend my time fighting against the third and much bigger thing, which Mood Machine alludes to in far less detail than the others, which is Spotify's relentless and deliberate subordination of music and culture and humanity to machine learning. "ML Is the Product", the executive exhortation went. I wrote an internal talk explaining exactly why this was a culture-destructive way to think, which I would also like back. I am enthusiastically not against the use of data and algorithms in music and thus culture, but computers are tools that accomplish our human intents, and it is thus us that should be judged on their effects. Over the years at Spotify I found that it was increasingly dishearteningly common that people, and especially hierarchical company priorities based on obtuse quantitative metrics, not only did not care about the widely varying effects of erratic ML on music, but didn't even notice that they often didn't have enough information with which to care. I developed a small library of internal tools that only existed to make it unignorably easy to compare the outputs of two different systems on any individual example, and every time I ever compared a complicated state-of-the-art ML system developed by demonstrably talented ML engineers against whatever I whipped up in BiqQuery and spent a couple of hours tweaking while looking at exactly what it did for different bands or genres or songs, the music results from the less-exciting tech were always clearly better.
And each time I did this, it renewed my uncooperative senses of possibility and optimism, because collective human knowledge is astonishingly broad and deep, and the world is full of amazingly great music, and it takes only a little bit of very simple math to use the former to discover the latter. This is what my decade at Spotify was about, and thus is also what my book is about. If you care about music, you ought to want to read Liz's book. But if you can also stand being reminded why anybody cares about this subject in the first place, whether you already thought you wanted that or not, read mine, too.
Should you read either of our books? No. Do it if you want, or read something else, or put on some music and go for a walk, or put on some music and dance or hold still. My book is geeky, and tells you things you don't really have to know. Liz's is depressing, and tells you things you could already have guessed.
I will say, though, that mine involves both fears and joys. Liz's could have, but does not. It's telling that she talked to so many people, but as far as I can tell only people who she already knew agreed with her. Liz and I were on a Pop Conference panel together in 2018, I've offered to talk to her multiple times over the years, and she quotes my tweets and this blog and discusses my work in the book, but she didn't talk to me. Her book is decent journalism, but it's journalism to explicate a grudge, to deepen understanding in only one specific trench. I don't think, when you get to the bottom of it, there's any treasure, or really anything productive to do except climb back out, and then we're just where we started. Liz makes a good case for public libraries collecting local music, which seems like a fine idea to me, but not really an answer to any of the same questions. Mood Machine laments the loss of small things Liz thinks we used to have, maybe, but doesn't seem interested in looking for any of the big things we could have had, and still might. If the problem is mood, I don't think this is the solution.
Not that I solved anything in my book, either. We both note that maybe Universal Basic Income is really the only thing likely to. But if you think the only moral direction is retreat, and the right model for music is that you never hear any unless it was made next door, then you are choosing passivity over curiosity, and just a different status quo over all the possible better worlds, and reducing a complicated problem to choosing sides. And to me that's what we should be against, together.
As a corporation, Spotify is very normal. Its Swedish origins render it slightly progressive in employment policies relative to American companies, at least if you want to have more children than you already have when you get hired, and can make sure to have them without getting laid off first. In business and product practices, I never saw much reason to consider it better or worse than what one would expect of a medium-to-large-sized publicly-traded tech company.
I arrived at Spotify involuntarily via an acquisition, and left involuntarily via a layoff, but in between those two events I was there voluntarily for a decade. I believe that music is what humans do best, and that bringing all(ish) of the world's music together online is one of the great human cultural achievements of my lifetime, and that the joy-amplifying potential of having the collective love and knowledge encoded in music-listening collated and given back to us is monumental. That's what I spent that decade working on, and although Spotify as a corporation finally voted decisively against this by laying me off and devoting considerable remaining resources to laboriously shutting down everything I worked on, I was hardly the only person working there who believed in music, and wanted there to be a music company that put music above "company", and wanted Spotify to behave in at least a few ways like that company.
It was never very likely to, of course. As Liz begrudgingly notes in her introduction, she set out to write an anti-Spotify book only to realize the problem wasn't really just Spotify so much as power. Spotify entered a music business largely controlled by a few record companies, at a point in history when the other confounding factors in the industry were already technological. Spotify did eventually come up with a few minorly novel forms of moral transgression, but they were never really in a position to explode the existing power structures, even if we could pretend they wanted to.
There were three specific things I fought against throughout my time at Spotify, and although my layoff was officially just part of a large impersonal reduction in "headcount", it's hard to imagine that there wasn't some connection. Mood Machine describes two of these in depressing detail: the secret preferential treatment of particular lower-royalty background music, and the not-secret "marketing" program to pressure artists to voluntarily accept lower royalty rates for the prospect of undisclosed algorithmic promotiom. Liz quotes multiple internal Spotify Slack messages about both these programs, and if somehow this ends up with all those grim private threads getting published, I'll be pleased to get so much of my earnest polemic-writing back. The quote from "yet another employee in the ethics-club" on pages 193-4, pointing out that Discovery Mode is exactly structured to benefit Spotify at the collective expense of artists, is definitely me. I'm pretty sure I went on to explain how to fix the economics of this by making Spotify's benefit conditional on artist benefit, and how to fix the morality of it by actually giving artists interesting agency instead of just an opportunity for submission. Sadly, Liz doesn't quote that part.
But I hadn't resigned in protest over PFC or Discovery Mode, partly because I didn't think either one actually caused sufficient practical damage that removing them would solve enough, but mostly because I had the autonomy and ability to spend my time fighting against the third and much bigger thing, which Mood Machine alludes to in far less detail than the others, which is Spotify's relentless and deliberate subordination of music and culture and humanity to machine learning. "ML Is the Product", the executive exhortation went. I wrote an internal talk explaining exactly why this was a culture-destructive way to think, which I would also like back. I am enthusiastically not against the use of data and algorithms in music and thus culture, but computers are tools that accomplish our human intents, and it is thus us that should be judged on their effects. Over the years at Spotify I found that it was increasingly dishearteningly common that people, and especially hierarchical company priorities based on obtuse quantitative metrics, not only did not care about the widely varying effects of erratic ML on music, but didn't even notice that they often didn't have enough information with which to care. I developed a small library of internal tools that only existed to make it unignorably easy to compare the outputs of two different systems on any individual example, and every time I ever compared a complicated state-of-the-art ML system developed by demonstrably talented ML engineers against whatever I whipped up in BiqQuery and spent a couple of hours tweaking while looking at exactly what it did for different bands or genres or songs, the music results from the less-exciting tech were always clearly better.
And each time I did this, it renewed my uncooperative senses of possibility and optimism, because collective human knowledge is astonishingly broad and deep, and the world is full of amazingly great music, and it takes only a little bit of very simple math to use the former to discover the latter. This is what my decade at Spotify was about, and thus is also what my book is about. If you care about music, you ought to want to read Liz's book. But if you can also stand being reminded why anybody cares about this subject in the first place, whether you already thought you wanted that or not, read mine, too.
Should you read either of our books? No. Do it if you want, or read something else, or put on some music and go for a walk, or put on some music and dance or hold still. My book is geeky, and tells you things you don't really have to know. Liz's is depressing, and tells you things you could already have guessed.
I will say, though, that mine involves both fears and joys. Liz's could have, but does not. It's telling that she talked to so many people, but as far as I can tell only people who she already knew agreed with her. Liz and I were on a Pop Conference panel together in 2018, I've offered to talk to her multiple times over the years, and she quotes my tweets and this blog and discusses my work in the book, but she didn't talk to me. Her book is decent journalism, but it's journalism to explicate a grudge, to deepen understanding in only one specific trench. I don't think, when you get to the bottom of it, there's any treasure, or really anything productive to do except climb back out, and then we're just where we started. Liz makes a good case for public libraries collecting local music, which seems like a fine idea to me, but not really an answer to any of the same questions. Mood Machine laments the loss of small things Liz thinks we used to have, maybe, but doesn't seem interested in looking for any of the big things we could have had, and still might. If the problem is mood, I don't think this is the solution.
Not that I solved anything in my book, either. We both note that maybe Universal Basic Income is really the only thing likely to. But if you think the only moral direction is retreat, and the right model for music is that you never hear any unless it was made next door, then you are choosing passivity over curiosity, and just a different status quo over all the possible better worlds, and reducing a complicated problem to choosing sides. And to me that's what we should be against, together.
¶ My year in music and yours · 6 January 2025 listen/tech
I think about music in years. 2024 was the first year in a long time that I didn't have anything to do with Spotify Wrapped, but that was never why I thought about music in years, and certainly never how. I like my music data to tell me stories about music not about graphic design, and in verifiable numbers not templated snarkiness. I want to stand at the end of one year and the brink of another and think clearly about how I've been listening, and thus living, and expansively about how I might.
You don't have to want what I want, but if you want to experiment with your Spotify listening data, I've built some tools to help you. To play, you need a computer and a Spotify premium account, and you need to do two things. One is this:
 - go to your Spotify Account page from the popup menu on your profile picture
- go to your Spotify Account page from the popup menu on your profile picture
- scroll down to the evasively named "Account privacy" link and click it
- scroll down the Account privacy page to the "Download your data" section
- check the box on the right under "Extended streaming history", and then the Request Data button at the bottom
While you wait for your data, which will take a couple days, do the other thing, which is to go to Curio, my web thing for collating music-data curiosity, and follow the instructions for getting a free Spotify API key. If you've already done that, just wait impatiently.
When you get your data files from Spotify, go to the History page in Curio and follow the instructions there to load your streaming history. (If the file names in the instructions don't match the files you got, you got the wrong data so go back and request the Extended streaming history like I said.)
You can ask your own questions about your data, but to get started I've already set up a bunch of views that I wanted for myself. Here is a mercilessly geeky tour of those, in which you will learn way more than you ever wanted to know about my year in music.
overview

I listen to music a lot, but never strictly as background, so not for as much time as I could physically. Apparently I went 17 whole days last year without playing any, which I admit is alarming negligence. The count under "tracks" is the strict computer version of counting in which listening to a single and then the exact same song on the album counts as 2 different things. The number under "songs" tries to account for this, although Spotify doesn't give us public access to their internal audio fingerprints, so I just do this by counting unique artist-id/song-title pairs. The "albums" number only counts the albums where I played at least two of their actual tracks (so not separate singles), although it doesn't matter whether they were played from the album page or from playlists. The "artists" number counts only the primary artists of each track. The "genres" number counts only the genres where I listened to stuff by at least 5 different artists. The "of" link at the end tells you that I had 22,423 total streams last year, and you can click your count to see yours, because that's how it should be with data.
tracks
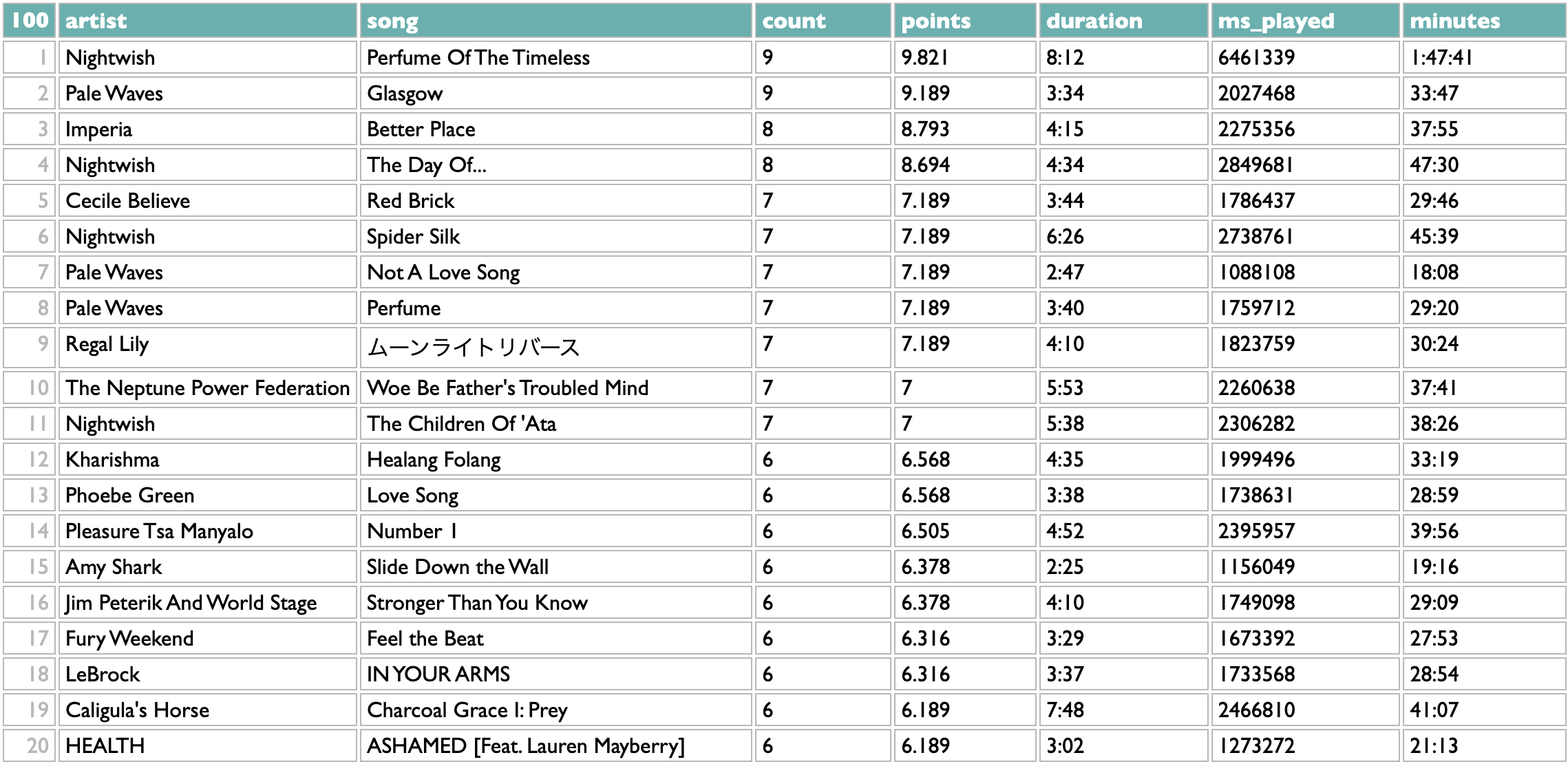
To me a "year in music" is the music that was released in a year. I listen mostly to new music, and all the personal 2024 stats I personally want to see are about my 2024 listening to 2024 music. But there's a "new releases"/"all releases" switcher at the top of most of these History views in Curio, and a separate "old releases" option for a few of them, in case you feel differently. The ranking of tracks is done with a points calculation that you can see for yourself by going to the "see the query for this" link below the table, but my philosophical position is that playing a song on loop for a while is better evidence of affection than playing it once, but not better evidence than returning to it deliberately over the course of different days, so I give each song the sum of 4th roots of its daily playcounts. (Why 4th roots? Square roots didn't mute the looping effect enough for my taste, and chaining two square-roots together worked enough better than I didn't bother adding a cube-root fucntion to the query-language yet. (Although there's also a way to do arbitrary math, so you could raise it to the power of a third, but let's not.)) I don't tend to repeat individual songs very much, so this view isn't my favorite way to look at my own history, but even so it's useful for cross-checking the playlist view that we'll get to at the end.
albums
I mostly listen via weekly playlists of new releases, usually with only one track per artist, and in the increasingly common case of waterfall releases where most of the tracks on an album are released individually before the whole album, it's common that I have listened to most of the contents of an album without directly playing the album much or at all. All of these, though, are cases where I cared enough to break my playlist pattern and play these whole albums. "ms_played" means milliseconds, and is the standard Spotify measurement of how much clock time you spent listening to a song independent of its duration, so if you end up doing your own queries you'll quickly get familiar with this. The query here does some fun stuff with song titles and release types to try to report the album/single dynamics of my listening, but it won't surprise me much if your listening has some edge cases I didn't catch in mine.
artists
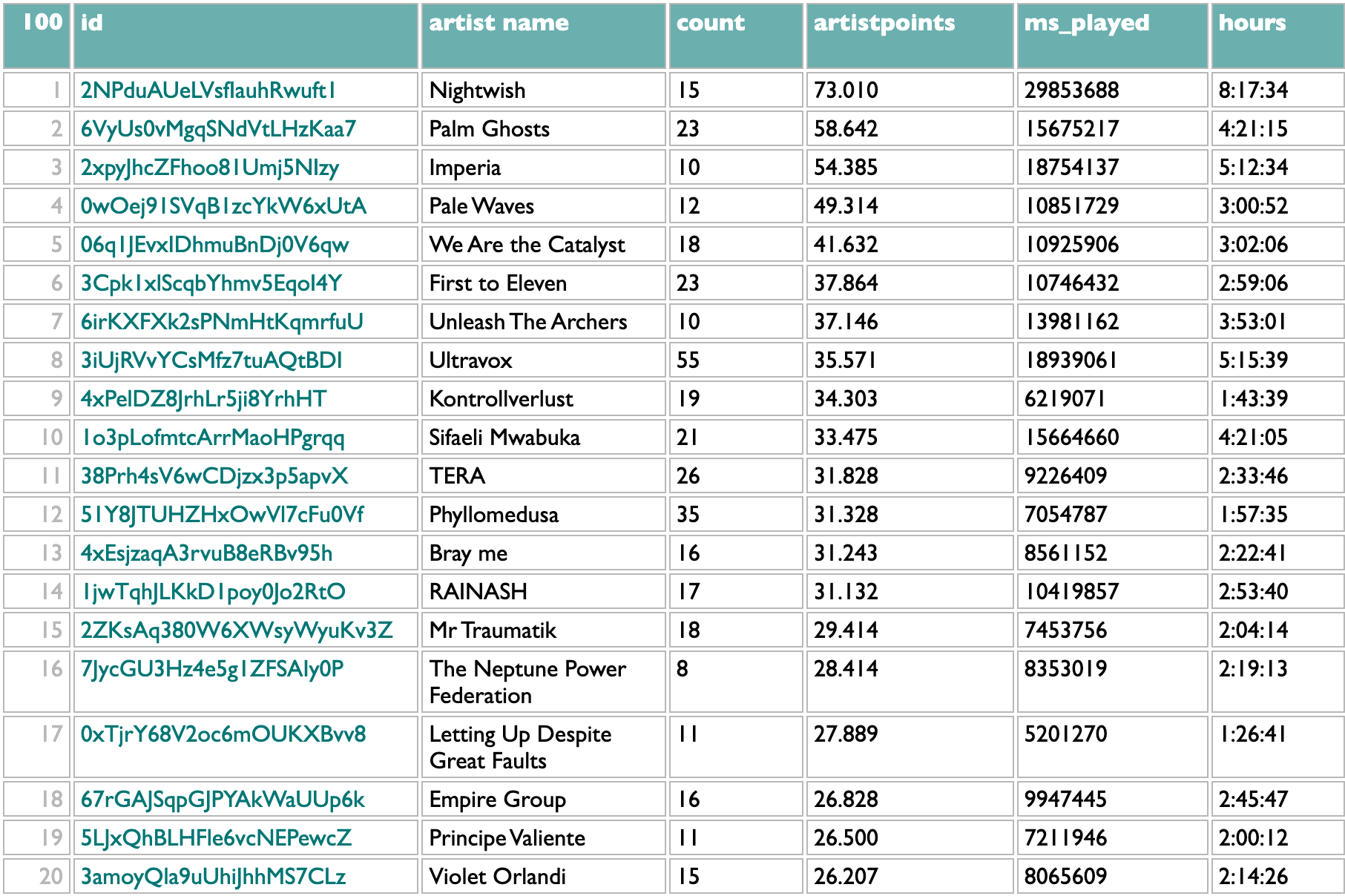
But really, my levels of attachment to music are, and have been for years, mostly artist and genre. Humans, individually and collectively. The track and album lists are, for me, steps on the way to this artist list. At the artist level, too, I am leery of overweighting isolated looping, so my artist point system sums up the square roots of the number of unique tracks by that artist played on each listening day. The "count" column here is the total number of unique new 2024 songs I played by each artist. This list is a pretty good telling of my 2024 music story to myself. I expect the chance is low that anybody other than me knows this specific combination of specific artists well enough to make sense of it. First to Eleven is a prolific pop-punk covers band who put out new songs every week or two. TERA is a strange home-demo-sounding vocaloid project that has survived me mostly rotating out of vocaloid music because their use of artificial voices is so artificial. Phyllomedusa is frog-themed grindcore. Sifaeli Mwabuka is a Swahili gospel singer from Tanzania, and I could not have told you his name and am probably as surprised as you that I spent more than four hours listening to him, but apparently he is what happens when you try to listen to both maskandi and Sepedi wedding music despite not really knowing much about either. But mainly what this tells you, as you already knew if you read my book or ever talked to me about music for longer than five minutes, is that I love Nightwish and they had a new album this year.
popularity
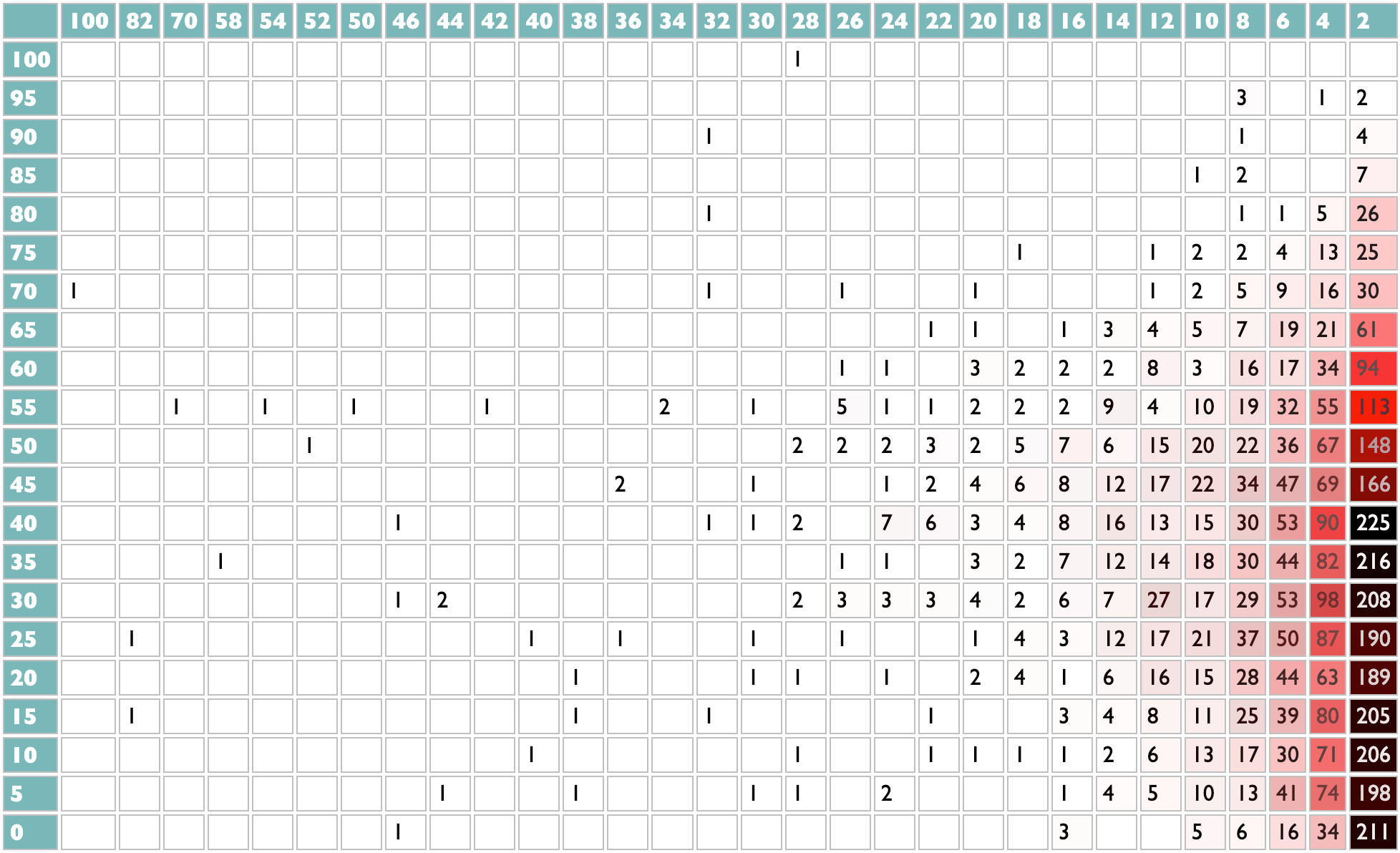
My favorite one-time thing I ever did for Spotify Wrapped was the Listening Personality, in 2022. It wasn't supposed to be a one-time virality-nudge, it was supposed to be the seed of a way for humans and algorithms to talk to each other about the aspects of music-preference that are independent of what kind of music you like. Spotify, sadly, was not as interested as I was in what people actually want, nor about using algorithms to amplify curiosity instead of, say, maximizing marginal revenue, so I never got to do more with the Listening Personality codes beyond showing them to people once, but at least I obstinately insisted on Wrapped displaying the four-letter Myers-Briggs-esque codes I devised for each listener, over the graphics team's predictable attempt to reduce the 16 combinations to unexplained tarot cards. (But don't worry, they got their tarot cards the next year.)
I can't exactly reproduce the Listening Personality with just our own listening histories, because the calibration of the polarities of each axis was done holistically across the whole Spotify population. But if we lose collective breadth, we gain individual depth. Instead of a single letter-pair encoding a single score representing how popular the music you tend to listen to tends to be, here we have a heatmap in which the X-axis is your level of artist attachment (scaled to 100 for your most-played artist) and the Y-axis is those artists' global popularities (scaled to 100 for Taylor). What my heatmap tells us is that I listen very broadly to a lot of artists who are not very popular but usually are also not entirely unknown. And I also do like Taylor. If you only listen to Taylor, your heatmap will be a single red cell in the top left with a number of which I assume you will be very proud.
diversity

Two of the other three dimensions of the Listening Personality had to do with how your listening is distributed or concentrated across artists and across songs. I am a fairly extreme outlier in the direction of variety in both, which we see here as a small explosion centered in the bottom (more artists) right (more songs). If you spent the year cycling through Taylor's Versions of everything, you would end up in the top left; if just covers of "Anti-Hero", a red line down the right edge. The axes here are not normalized, because I no longer have access to everybody else's data to figure out a generalized granularity, so your own version of this view may be comically small or awkwardly large.
genres
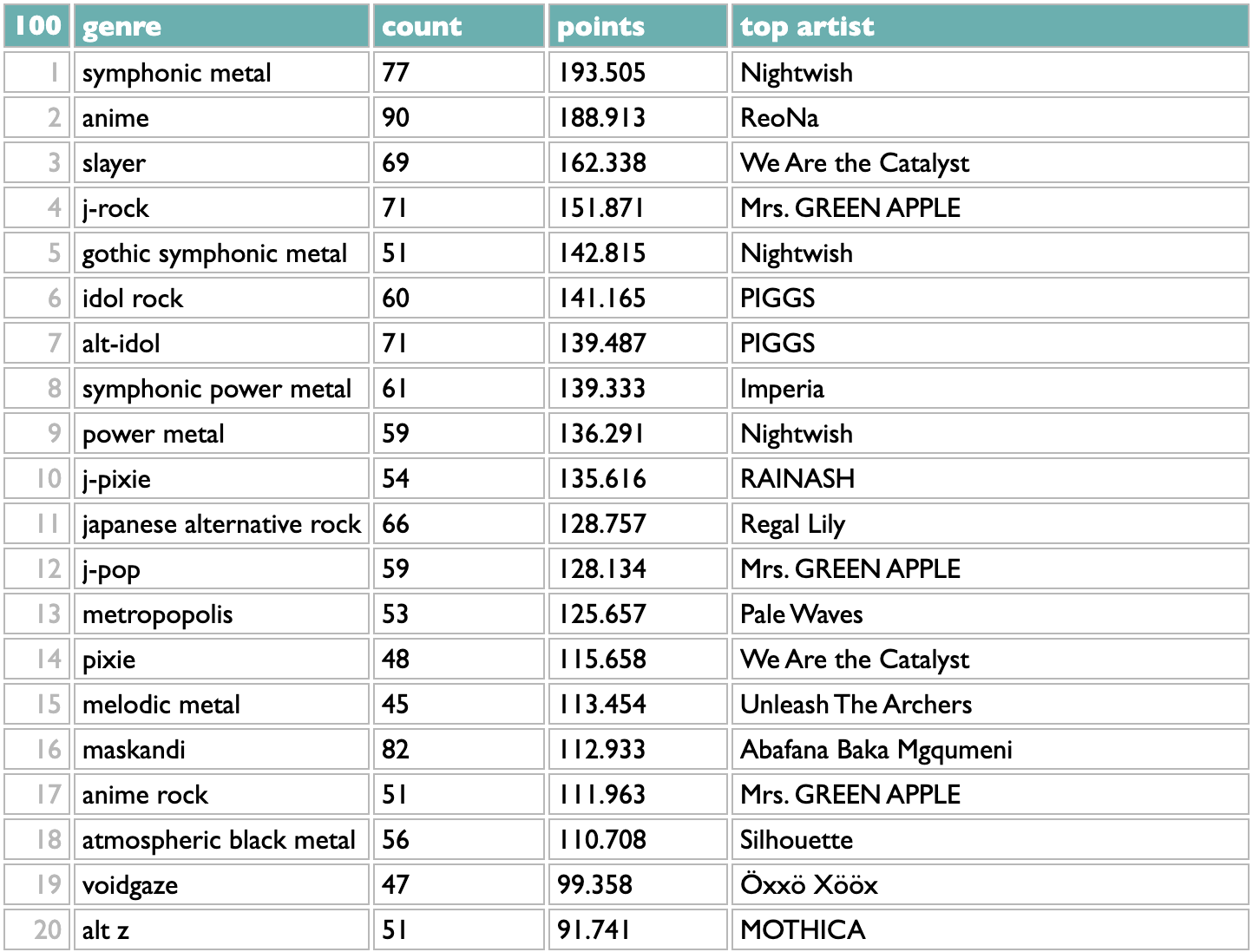
The Wrapped story I worked on every year (although one year they substituted something else without having the guts to tell me they were going to) was the list of your Top Genres. I have taken some shit over the years for occasionally making up genre names, but if you want to know what the point of that was, there's a whole chapter about it in my book, and after seeing the 2024 Wrapped in which Spotify ditched the whole concept of genres as human musical community and generated idiotic random phrases instead, I feel 100% comfortable with what I did. Every year as we started making plans for Wrapped I said the same three things: 1) I will do the genre analysis so it's right, because these are real communities of artists and listeners in the real world and they deserve to see themselves. 2) Let's show people all their genres instead of just five. 3) And let's also let people see which artists (both in general and that you like) go with each genre, so the whole thing isn't mysterious. And every year the "creative" team said something like "Or what if we show the same unexplained list of five, but as a spinning hamburger made of radioactive sludge?"
Curio's version is obdurately sparkleless but sludgeless: all your genres, ranked with artisanally hand-tuned scoring, and clickable in your version to see exactly which of your artists make up each list.
words

My favorite story I proposed for Wrapped, knowing full-well that it would never get approved, ironically did involve generating random phrases for people, but the way I did it was from the words in the titles of the songs you played, so even this totally frivolous thing was explainable and there was a sense in which it could be correct. The key to getting a short list of pertinent words is having the whole population's listening to work with, so you can give each person the few words that most distinctively characterize their listening. Without that global data I am forced to give you lots of words instead of a few, in a weighted shuffle to avoid everybody's saying love death soundtrack day, but hopefully yours, like mine, will including something true and vulgar that will make you smile and would make lawyers panic.
durations
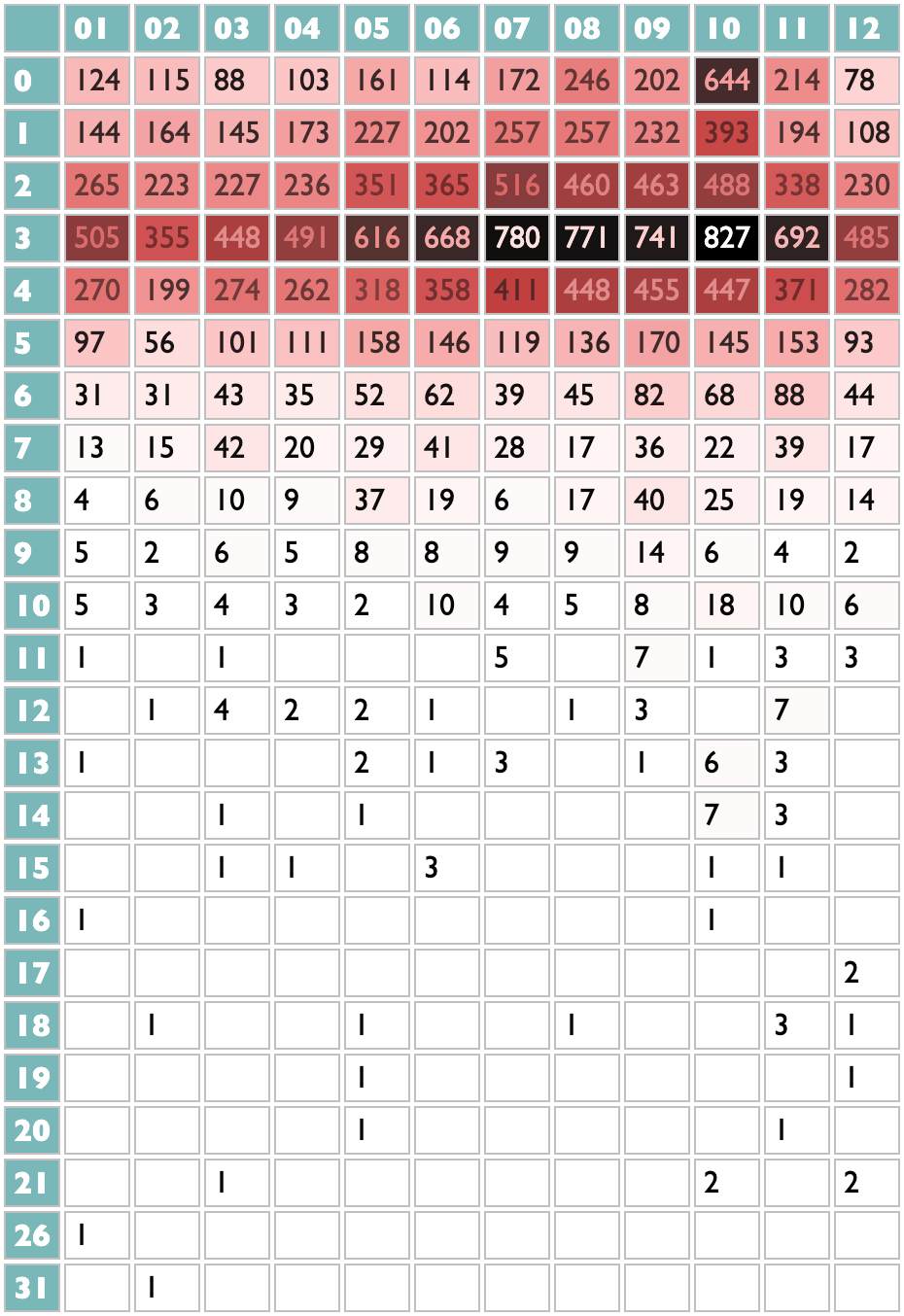
People talk about pop songs and attention spans both getting shorter, and we have all those milliseconds, so this one is a view of your listening (by month, for fun, across the top) distributed by how long you listened to each track (in minutes, down the left). I listen to a lot of three-minute songs. I listen to a few seconds of a lot of songs and then skip. I listen to some long songs. Apparently in October I was working on getting the track-scan timings right in Curio.
daymap
Everything you play on a streaming service is timestamped. In Spotify's case the timestamps are in UTC, so I included a timeshift option to allow you to bump them into your local time, or adjust your listening day some other way if you prefer. I'm not going to include my daymap, here, because it shows you every timestamp from the entire year and I realize looking at it that immediately reveals exactly when I traveled to a different time zone this year, and maybe that's more sharing than I need.
weekmap
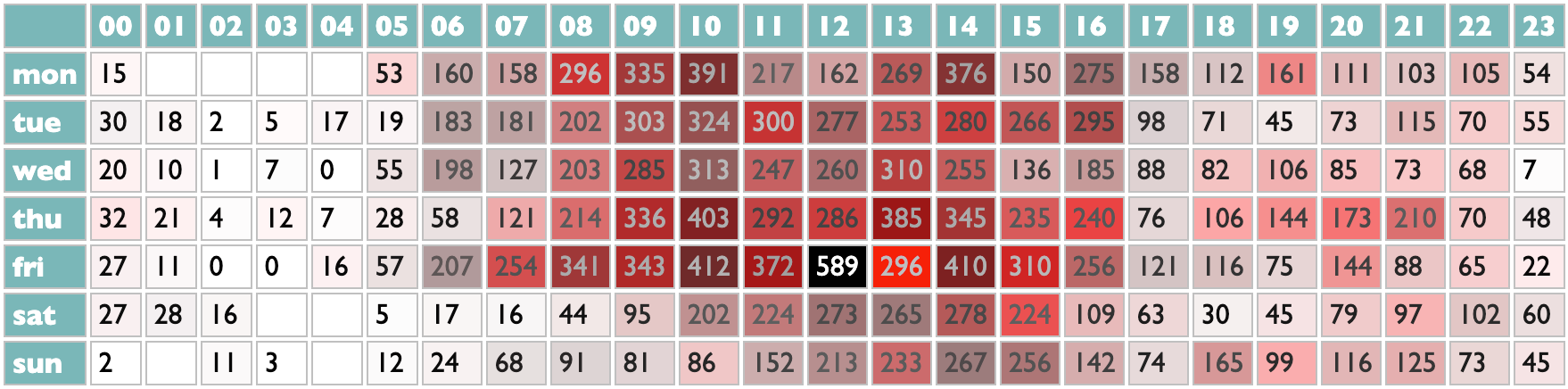
Musically speaking, though, the view by hour and weekday is more relevant. Spotify spent a lot of energy, over the years, trying to believe that most people's listening is heavily determined by day and time, and if yours is, now you have a playlist feature for that in Spotify. Mine isn't. I make a playlist of new songs I want to hear every Friday, and then I cycle through it, gradually deleting songs I don't end up enjoying, for the rest of the week. Thus there is absolutely no sense in which a have different music I prefer on Tuesday afternoon vs Thursday morning. What I do have, as you see here, is a very distinct pattern of doing a lot of rapid new-song scanning while eating my lunch on Fridays. Also, hopefully I do not have any important online accounts for which the security question is "At what hour are you most likely to be asleep?"
release years
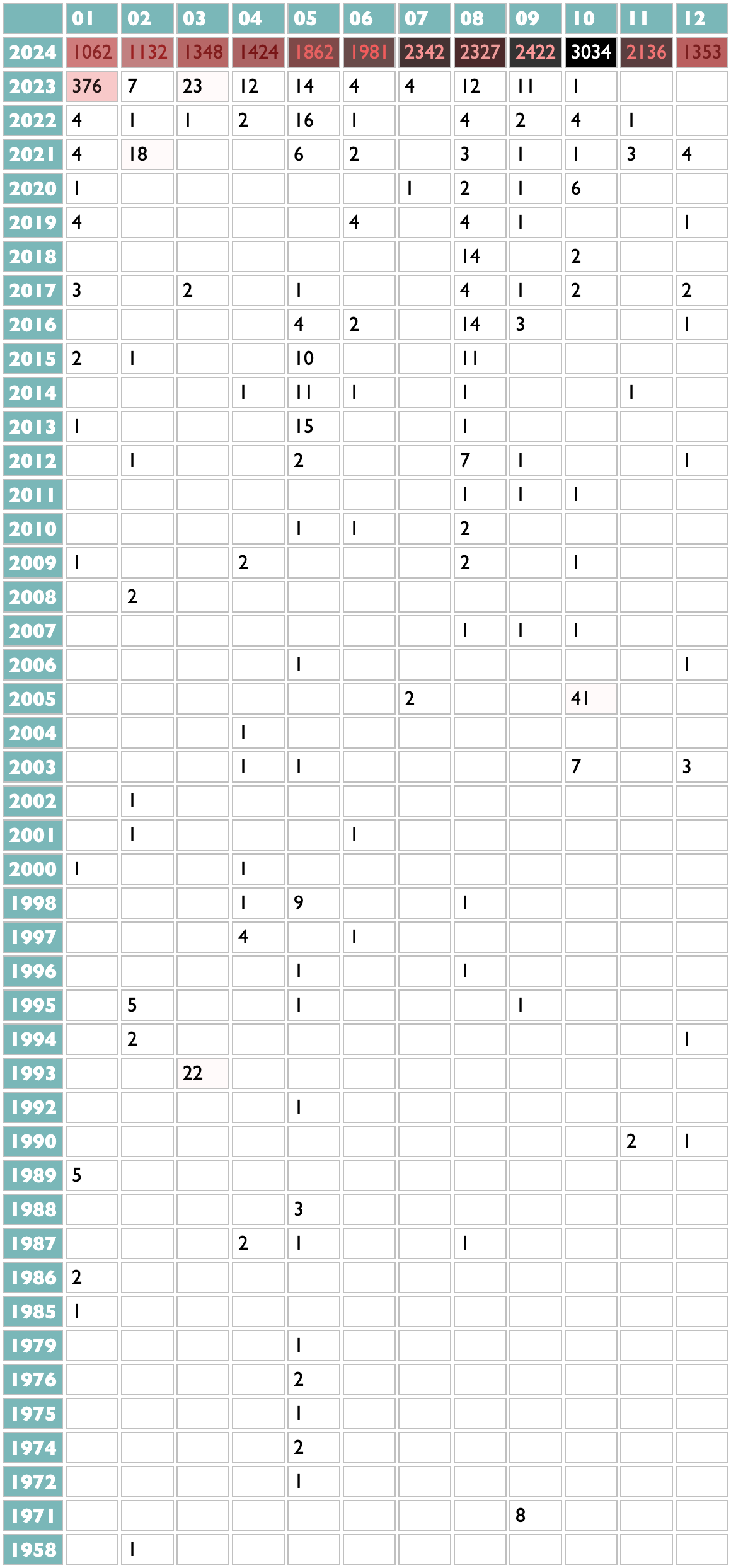
The fourth dimension in the Listening Personality was newness. I know, from data, that I am, or at least for a few years provably was, one of the handful of people in the world whose listening is most intently focused on new music. Curio thus has two different ways of looking at this particular quirk. This first one shows release years by listening months, so you can see how I listen to songs from the previous year for at least the first week of January, and how in May last year I tried and ultimately failed to find or remember one particular Ray Charles song.
song ages
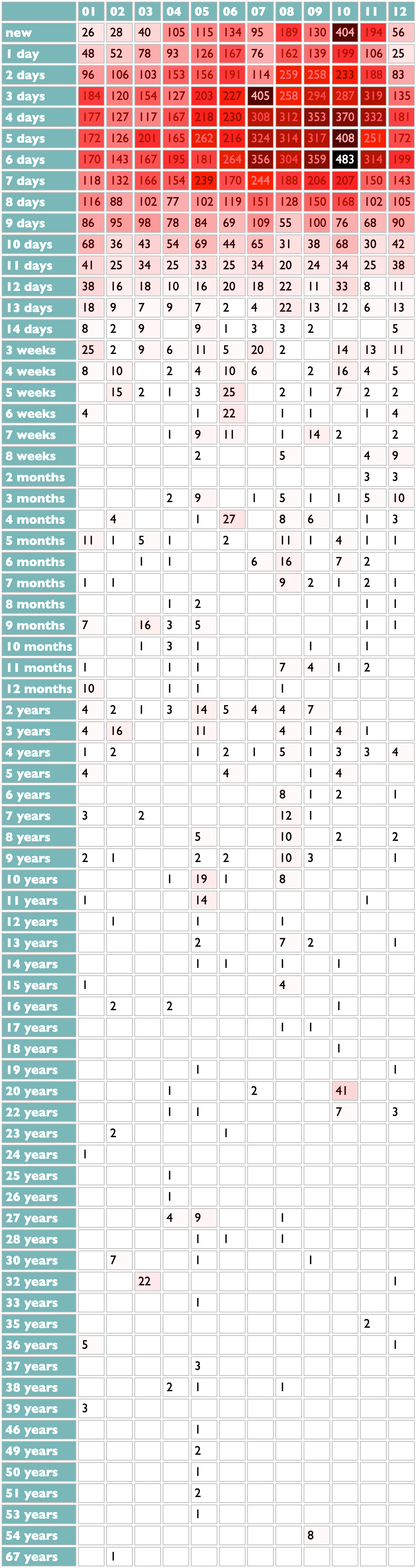
My listening pattern is even clearer in this view by song age, with ascending resolution. Friday is new-release day, but I am often distracted from listening over the weekends, so Monday through Thursday I am most heavily playing the songs from the previous Friday.
poster

As you may already realize, my taste in visual design runs to the Tuftean. Don't make me justify the horizonal rule in this poster view to ET, but the order and sizes and colors here are all data-driven, and yet it's still faintly reminiscent of a concert-poster design.
10x10 grid
5x5 grid

banner

If I want a visual summary of my year in music, it should definitely be made out of the visual art that is already attached to the music, not something else.
playlist
open this playlist in Spotify
The playlist, at least for me, is the authoritative final summary. It's my year in music, so it better be made of music, and it better make sense to me when I play it.
Spotify makes you a playlist, too, called Your Top Songs. It's fine, in that so far they haven't decided to screw it up with any kind of machine learning. It's never what I want, personally, because it ignores release dates and it has mutiple songs per artist and it doesn't sort the way I want.
What I want, and thus built, is not a Top Songs playlist, but an attempt at a playlist that represents a listening year. To do this it starts from the artist list, not song list, and then tries to pick your most-played new song from each of those artists.
Here's what that looks like in Dactal query syntax, as you can see if you click the "see the query for this" link at the bottom of the playlist table, except I've added a little color-coding:
The red parts are the artist query, which goes like this:
- get all your 2024 tracks (from a previous query)
- group these by each track's first artist, song name and date
- assign the square root of the number of times you played that artist/song that day as songdatepoints
- group those artist/song/date groups by artist and song
- total the songdatepoints from all dates per artist/song
- also total the amount of time you played this artist/song
- sort and rank the artist/song groups by songpoints and then songtime (in both cases from larger to smaller)
- group those artist/song groups by artist
- assign each artist a total artistpoints value that is the sum of songpoints-.5 (to reduce the weight of lots of songs you only played once)
- total up the amount of time you listened to that artist
The playlist query inserts one more line (an annotation suboperation) to calculate each artist's topsong for the playlist by taking the artist's highest-ranking artist/song group and getting an album track if one is available from the potentially multiple tracks representing that song, and the one you streamed first otherwise.
The artist query already sorts the artists by artistpoints and then listening time, which is the same order I wanted for the playlist. The :@<=100 picks the first 100, and the final block in parentheses just constructs some nicer columns for the final view. Curio watches for query results with uri columns, and offers to make them into a playlist for you, as you'll see.
The other thing I always wanted in Wrapped and never got, however, is the ability to remove things. Sometimes it's technically true that you played a song a lot, but not emotionally true that you liked it. Or, in my case, it's technically true that the reissue of Ultravox's Lament is a 2024 release, but I don't consider new repackagings of old recordings of "Dancing With Tears in My Eyes" to be new songs, so I prefer to remove that one. The chaining nature of Dactal makes this easy. That final sorting/filtering line just becomes
with the limit filter still at the end so we get 100 tracks instead of 99 despite dropping one. It would also be possible to filter Ultravox out at the artist level, or Lament out at the album level, but it doesn't make any difference to the results.
That's all what Curio gives you, including deleting tracks:

But this still isn't quite what I want, and I am stubborn. I make playlists every week, during the year, and these sometimes represent my decisions, after a week of listening to more than one track from an album, which one to keep. And it's not always the one I played the most times. Curio already has this playlist data, or can have it, if you provide an indexing pattern at the bottom of the Playlists page. This can be as simple as * to index everything, but I have lots of playlists that I made for reasons other than my taste, so I only index these two particular sets:

(End partial matches with asterisks, and separate multiple patterns with a space, so the commas here are part of the matching patterns.)
So my own personal variation adds one more wrinkle to the artist/song-group sorting:
The songkey line computes an artist/song key-string, which the s2pa line then uses to navigate into another dataset, itself produced by a query, that indexes playlist appearances by those same artist/song keys. I could use this dataset join to sort tracks by playlist counts or dates or anything, but all I really want to do is prefer tracks that I put on a playlist to ones I didn't, if there's a choice. So the .(1) part results in a 1 for songkeys that are in the songkey to playlist apperances dataset, and nothing for songkeys that aren't, and Dactal always sorts something before nothing.
There is absolutely no way that you could possibly tell the difference between me doing this and not, nor any reason you should care, but I care. What you choose to care about, in your own data and life, is your business, but the moral function of software is to let us express our care, and thus to encourage us to realize we have it. Your data is yours. The stories it tells are your stories. You should want them to be right, and nobody but you should get to tell you what that right is.
You don't have to care, but I want you to. The more we all care about everything, the less we will tolerate it any of it being bad.
You don't have to want what I want, but if you want to experiment with your Spotify listening data, I've built some tools to help you. To play, you need a computer and a Spotify premium account, and you need to do two things. One is this:
- go to your Spotify Account page from the popup menu on your profile picture
- scroll down to the evasively named "Account privacy" link and click it
- scroll down the Account privacy page to the "Download your data" section
- check the box on the right under "Extended streaming history", and then the Request Data button at the bottom
While you wait for your data, which will take a couple days, do the other thing, which is to go to Curio, my web thing for collating music-data curiosity, and follow the instructions for getting a free Spotify API key. If you've already done that, just wait impatiently.
When you get your data files from Spotify, go to the History page in Curio and follow the instructions there to load your streaming history. (If the file names in the instructions don't match the files you got, you got the wrong data so go back and request the Extended streaming history like I said.)
You can ask your own questions about your data, but to get started I've already set up a bunch of views that I wanted for myself. Here is a mercilessly geeky tour of those, in which you will learn way more than you ever wanted to know about my year in music.
overview

I listen to music a lot, but never strictly as background, so not for as much time as I could physically. Apparently I went 17 whole days last year without playing any, which I admit is alarming negligence. The count under "tracks" is the strict computer version of counting in which listening to a single and then the exact same song on the album counts as 2 different things. The number under "songs" tries to account for this, although Spotify doesn't give us public access to their internal audio fingerprints, so I just do this by counting unique artist-id/song-title pairs. The "albums" number only counts the albums where I played at least two of their actual tracks (so not separate singles), although it doesn't matter whether they were played from the album page or from playlists. The "artists" number counts only the primary artists of each track. The "genres" number counts only the genres where I listened to stuff by at least 5 different artists. The "of" link at the end tells you that I had 22,423 total streams last year, and you can click your count to see yours, because that's how it should be with data.
tracks

To me a "year in music" is the music that was released in a year. I listen mostly to new music, and all the personal 2024 stats I personally want to see are about my 2024 listening to 2024 music. But there's a "new releases"/"all releases" switcher at the top of most of these History views in Curio, and a separate "old releases" option for a few of them, in case you feel differently. The ranking of tracks is done with a points calculation that you can see for yourself by going to the "see the query for this" link below the table, but my philosophical position is that playing a song on loop for a while is better evidence of affection than playing it once, but not better evidence than returning to it deliberately over the course of different days, so I give each song the sum of 4th roots of its daily playcounts. (Why 4th roots? Square roots didn't mute the looping effect enough for my taste, and chaining two square-roots together worked enough better than I didn't bother adding a cube-root fucntion to the query-language yet. (Although there's also a way to do arbitrary math, so you could raise it to the power of a third, but let's not.)) I don't tend to repeat individual songs very much, so this view isn't my favorite way to look at my own history, but even so it's useful for cross-checking the playlist view that we'll get to at the end.
albums

I mostly listen via weekly playlists of new releases, usually with only one track per artist, and in the increasingly common case of waterfall releases where most of the tracks on an album are released individually before the whole album, it's common that I have listened to most of the contents of an album without directly playing the album much or at all. All of these, though, are cases where I cared enough to break my playlist pattern and play these whole albums. "ms_played" means milliseconds, and is the standard Spotify measurement of how much clock time you spent listening to a song independent of its duration, so if you end up doing your own queries you'll quickly get familiar with this. The query here does some fun stuff with song titles and release types to try to report the album/single dynamics of my listening, but it won't surprise me much if your listening has some edge cases I didn't catch in mine.
artists

But really, my levels of attachment to music are, and have been for years, mostly artist and genre. Humans, individually and collectively. The track and album lists are, for me, steps on the way to this artist list. At the artist level, too, I am leery of overweighting isolated looping, so my artist point system sums up the square roots of the number of unique tracks by that artist played on each listening day. The "count" column here is the total number of unique new 2024 songs I played by each artist. This list is a pretty good telling of my 2024 music story to myself. I expect the chance is low that anybody other than me knows this specific combination of specific artists well enough to make sense of it. First to Eleven is a prolific pop-punk covers band who put out new songs every week or two. TERA is a strange home-demo-sounding vocaloid project that has survived me mostly rotating out of vocaloid music because their use of artificial voices is so artificial. Phyllomedusa is frog-themed grindcore. Sifaeli Mwabuka is a Swahili gospel singer from Tanzania, and I could not have told you his name and am probably as surprised as you that I spent more than four hours listening to him, but apparently he is what happens when you try to listen to both maskandi and Sepedi wedding music despite not really knowing much about either. But mainly what this tells you, as you already knew if you read my book or ever talked to me about music for longer than five minutes, is that I love Nightwish and they had a new album this year.
popularity

My favorite one-time thing I ever did for Spotify Wrapped was the Listening Personality, in 2022. It wasn't supposed to be a one-time virality-nudge, it was supposed to be the seed of a way for humans and algorithms to talk to each other about the aspects of music-preference that are independent of what kind of music you like. Spotify, sadly, was not as interested as I was in what people actually want, nor about using algorithms to amplify curiosity instead of, say, maximizing marginal revenue, so I never got to do more with the Listening Personality codes beyond showing them to people once, but at least I obstinately insisted on Wrapped displaying the four-letter Myers-Briggs-esque codes I devised for each listener, over the graphics team's predictable attempt to reduce the 16 combinations to unexplained tarot cards. (But don't worry, they got their tarot cards the next year.)
I can't exactly reproduce the Listening Personality with just our own listening histories, because the calibration of the polarities of each axis was done holistically across the whole Spotify population. But if we lose collective breadth, we gain individual depth. Instead of a single letter-pair encoding a single score representing how popular the music you tend to listen to tends to be, here we have a heatmap in which the X-axis is your level of artist attachment (scaled to 100 for your most-played artist) and the Y-axis is those artists' global popularities (scaled to 100 for Taylor). What my heatmap tells us is that I listen very broadly to a lot of artists who are not very popular but usually are also not entirely unknown. And I also do like Taylor. If you only listen to Taylor, your heatmap will be a single red cell in the top left with a number of which I assume you will be very proud.
diversity

Two of the other three dimensions of the Listening Personality had to do with how your listening is distributed or concentrated across artists and across songs. I am a fairly extreme outlier in the direction of variety in both, which we see here as a small explosion centered in the bottom (more artists) right (more songs). If you spent the year cycling through Taylor's Versions of everything, you would end up in the top left; if just covers of "Anti-Hero", a red line down the right edge. The axes here are not normalized, because I no longer have access to everybody else's data to figure out a generalized granularity, so your own version of this view may be comically small or awkwardly large.
genres

The Wrapped story I worked on every year (although one year they substituted something else without having the guts to tell me they were going to) was the list of your Top Genres. I have taken some shit over the years for occasionally making up genre names, but if you want to know what the point of that was, there's a whole chapter about it in my book, and after seeing the 2024 Wrapped in which Spotify ditched the whole concept of genres as human musical community and generated idiotic random phrases instead, I feel 100% comfortable with what I did. Every year as we started making plans for Wrapped I said the same three things: 1) I will do the genre analysis so it's right, because these are real communities of artists and listeners in the real world and they deserve to see themselves. 2) Let's show people all their genres instead of just five. 3) And let's also let people see which artists (both in general and that you like) go with each genre, so the whole thing isn't mysterious. And every year the "creative" team said something like "Or what if we show the same unexplained list of five, but as a spinning hamburger made of radioactive sludge?"
Curio's version is obdurately sparkleless but sludgeless: all your genres, ranked with artisanally hand-tuned scoring, and clickable in your version to see exactly which of your artists make up each list.
words

My favorite story I proposed for Wrapped, knowing full-well that it would never get approved, ironically did involve generating random phrases for people, but the way I did it was from the words in the titles of the songs you played, so even this totally frivolous thing was explainable and there was a sense in which it could be correct. The key to getting a short list of pertinent words is having the whole population's listening to work with, so you can give each person the few words that most distinctively characterize their listening. Without that global data I am forced to give you lots of words instead of a few, in a weighted shuffle to avoid everybody's saying love death soundtrack day, but hopefully yours, like mine, will including something true and vulgar that will make you smile and would make lawyers panic.
durations

People talk about pop songs and attention spans both getting shorter, and we have all those milliseconds, so this one is a view of your listening (by month, for fun, across the top) distributed by how long you listened to each track (in minutes, down the left). I listen to a lot of three-minute songs. I listen to a few seconds of a lot of songs and then skip. I listen to some long songs. Apparently in October I was working on getting the track-scan timings right in Curio.
daymap
Everything you play on a streaming service is timestamped. In Spotify's case the timestamps are in UTC, so I included a timeshift option to allow you to bump them into your local time, or adjust your listening day some other way if you prefer. I'm not going to include my daymap, here, because it shows you every timestamp from the entire year and I realize looking at it that immediately reveals exactly when I traveled to a different time zone this year, and maybe that's more sharing than I need.
weekmap

Musically speaking, though, the view by hour and weekday is more relevant. Spotify spent a lot of energy, over the years, trying to believe that most people's listening is heavily determined by day and time, and if yours is, now you have a playlist feature for that in Spotify. Mine isn't. I make a playlist of new songs I want to hear every Friday, and then I cycle through it, gradually deleting songs I don't end up enjoying, for the rest of the week. Thus there is absolutely no sense in which a have different music I prefer on Tuesday afternoon vs Thursday morning. What I do have, as you see here, is a very distinct pattern of doing a lot of rapid new-song scanning while eating my lunch on Fridays. Also, hopefully I do not have any important online accounts for which the security question is "At what hour are you most likely to be asleep?"
release years

The fourth dimension in the Listening Personality was newness. I know, from data, that I am, or at least for a few years provably was, one of the handful of people in the world whose listening is most intently focused on new music. Curio thus has two different ways of looking at this particular quirk. This first one shows release years by listening months, so you can see how I listen to songs from the previous year for at least the first week of January, and how in May last year I tried and ultimately failed to find or remember one particular Ray Charles song.
song ages

My listening pattern is even clearer in this view by song age, with ascending resolution. Friday is new-release day, but I am often distracted from listening over the weekends, so Monday through Thursday I am most heavily playing the songs from the previous Friday.
poster

As you may already realize, my taste in visual design runs to the Tuftean. Don't make me justify the horizonal rule in this poster view to ET, but the order and sizes and colors here are all data-driven, and yet it's still faintly reminiscent of a concert-poster design.
10x10 grid

5x5 grid

banner

If I want a visual summary of my year in music, it should definitely be made out of the visual art that is already attached to the music, not something else.
playlist

open this playlist in Spotify
The playlist, at least for me, is the authoritative final summary. It's my year in music, so it better be made of music, and it better make sense to me when I play it.
Spotify makes you a playlist, too, called Your Top Songs. It's fine, in that so far they haven't decided to screw it up with any kind of machine learning. It's never what I want, personally, because it ignores release dates and it has mutiple songs per artist and it doesn't sort the way I want.
What I want, and thus built, is not a Top Songs playlist, but an attempt at a playlist that represents a listening year. To do this it starts from the artist list, not song list, and then tries to pick your most-played new song from each of those artists.
Here's what that looks like in Dactal query syntax, as you can see if you click the "see the query for this" link at the bottom of the playlist table, except I've added a little color-coding:
2024 tracks full
/artist=(.track info.artists:@1),song=(.track info.name),date
|songdatepoints=(....count,sqrt)
/artist,song
||songpoints=(..of...songdatepoints,total),
songtime=(..of..of....ms_played,total)
#rank=songpoints,songtime
/artist
|artistpoints=(.of..songpoints..(...._,(0.5),difference)....total),
ms_played=(..of..songtime,total),
topsong=(.of:@1.of#(.of.track info.album:album_type=album),(.of.ts):@1.of.track info)
#artistpoints,ms_played:@<=100
.(...artistpoints=artistpoints,
duration=(.topsong....duration_ms,mmss),
artist=(.topsong.artists:@1.name),
track=(.topsong.name),
uri=(.topsong.uri))
/artist=(.track info.artists:@1),song=(.track info.name),date
|songdatepoints=(....count,sqrt)
/artist,song
||songpoints=(..of...songdatepoints,total),
songtime=(..of..of....ms_played,total)
#rank=songpoints,songtime
/artist
|artistpoints=(.of..songpoints..(...._,(0.5),difference)....total),
ms_played=(..of..songtime,total),
topsong=(.of:@1.of#(.of.track info.album:album_type=album),(.of.ts):@1.of.track info)
#artistpoints,ms_played:@<=100
.(...artistpoints=artistpoints,
duration=(.topsong....duration_ms,mmss),
artist=(.topsong.artists:@1.name),
track=(.topsong.name),
uri=(.topsong.uri))
The red parts are the artist query, which goes like this:
- get all your 2024 tracks (from a previous query)
- group these by each track's first artist, song name and date
- assign the square root of the number of times you played that artist/song that day as songdatepoints
- group those artist/song/date groups by artist and song
- total the songdatepoints from all dates per artist/song
- also total the amount of time you played this artist/song
- sort and rank the artist/song groups by songpoints and then songtime (in both cases from larger to smaller)
- group those artist/song groups by artist
- assign each artist a total artistpoints value that is the sum of songpoints-.5 (to reduce the weight of lots of songs you only played once)
- total up the amount of time you listened to that artist
The playlist query inserts one more line (an annotation suboperation) to calculate each artist's topsong for the playlist by taking the artist's highest-ranking artist/song group and getting an album track if one is available from the potentially multiple tracks representing that song, and the one you streamed first otherwise.
The artist query already sorts the artists by artistpoints and then listening time, which is the same order I wanted for the playlist. The :@<=100 picks the first 100, and the final block in parentheses just constructs some nicer columns for the final view. Curio watches for query results with uri columns, and offers to make them into a playlist for you, as you'll see.
The other thing I always wanted in Wrapped and never got, however, is the ability to remove things. Sometimes it's technically true that you played a song a lot, but not emotionally true that you liked it. Or, in my case, it's technically true that the reissue of Ultravox's Lament is a 2024 release, but I don't consider new repackagings of old recordings of "Dancing With Tears in My Eyes" to be new songs, so I prefer to remove that one. The chaining nature of Dactal makes this easy. That final sorting/filtering line just becomes
#artistpoints,ms_played:uri-=[spotify:track:3sJYcbQ3CQCpCajduB9UK2]:@<=100
with the limit filter still at the end so we get 100 tracks instead of 99 despite dropping one. It would also be possible to filter Ultravox out at the artist level, or Lament out at the album level, but it doesn't make any difference to the results.
That's all what Curio gives you, including deleting tracks:

But this still isn't quite what I want, and I am stubborn. I make playlists every week, during the year, and these sometimes represent my decisions, after a week of listening to more than one track from an album, which one to keep. And it's not always the one I played the most times. Curio already has this playlist data, or can have it, if you provide an indexing pattern at the bottom of the Playlists page. This can be as simple as * to index everything, but I have lots of playlists that I made for reasons other than my taste, so I only index these two particular sets:

(End partial matches with asterisks, and separate multiple patterns with a space, so the commas here are part of the matching patterns.)
So my own personal variation adds one more wrinkle to the artist/song-group sorting:
/artist,song<
||songpoints=(..of...songdatepoints,total),
songtime=(..of..of....ms_played,total),
songkey=(....(.artist.id),song,concatenate),
s2pa=(.songkey.songkey to playlist appearances.(1))
#rank=s2pa,songpoints,songtime
||songpoints=(..of...songdatepoints,total),
songtime=(..of..of....ms_played,total),
songkey=(....(.artist.id),song,concatenate),
s2pa=(.songkey.songkey to playlist appearances.(1))
#rank=s2pa,songpoints,songtime
The songkey line computes an artist/song key-string, which the s2pa line then uses to navigate into another dataset, itself produced by a query, that indexes playlist appearances by those same artist/song keys. I could use this dataset join to sort tracks by playlist counts or dates or anything, but all I really want to do is prefer tracks that I put on a playlist to ones I didn't, if there's a choice. So the .(1) part results in a 1 for songkeys that are in the songkey to playlist apperances dataset, and nothing for songkeys that aren't, and Dactal always sorts something before nothing.
There is absolutely no way that you could possibly tell the difference between me doing this and not, nor any reason you should care, but I care. What you choose to care about, in your own data and life, is your business, but the moral function of software is to let us express our care, and thus to encourage us to realize we have it. Your data is yours. The stories it tells are your stories. You should want them to be right, and nobody but you should get to tell you what that right is.
You don't have to care, but I want you to. The more we all care about everything, the less we will tolerate it any of it being bad.
¶ Data Rights · 22 December 2024 essay/tech
Your data is yours. Data derived from your actions, your tastes, your active and passive online presences, is all your data. Your public life generates public data, which contributes to collective knowledge, but in addition to personal knowledge, not in place of it.
You are entitled to both your public and private data. Your public data can be used by the public without your consent, but not without your awareness and their accountability. You are entitled to an intelligible and verifiable explanation of how it has been used. You are entitled to be able to double-check the sorting of your Spotify Wrapped just as you can double-check the math for the interest payments from your savings account.
You may choose to share your private data with other people, or applications, or corporations, in order to let them do something for you, or to help you do something for other people. For this your informed consent is necessary, and thus you are entitled to an intelligible and verifiable explanation of how your data would be used if you permit. You are entitled to know what Spotify would do with your Wrapped before you decide whether to join.
This is the world we have now:
you < corporations > software > your data
This is the world we want:
you > your data > software > corporations
The actors are the same, but the roles and the power are not. Today most computational power is structurally centralized and hoarded, and thus its potential for conversion into human energy is constrained and reduced. Most software is made by corporations, formulated for their corporate goals, and sealed against any other access or experimentation. Recent developments like LLM AIs seem inertially on a path towards even more centralized power-control and thus individual and social powerlessness.
We want a future, instead, in which creative power is widely distributed and human energy is bountifully amplified. We want software creation to be democratized so that our sources of imagination can be more broadly recruited. We want people and groups to have the power to pursue their own goals, not just for our own narrow sakes, but for our collective potential.
For this world to exist, we must figure out how, both logistically and politically, to move the data layer on which most meaningful software acts into the computational and conversational open. We need not just data portability -- the right to chose between evils -- but a shared language for talking about algorithms and data logic like we use math to discuss numbers. We need to be able to talk about what we want, and test what we might have and how.
This is how the AT Protocol, on which the social microblogging platform Bluesky runs, is designed. Its schemas are public, its public information is public. Bluesky, the application, makes use of this protocol and your data to construct a social experience for you and with you, producing feeds and following and public conversations and personal data ownership. The Bluesky software is open source, and most of the data relationships that constitute the social network are derivable from accessible data in tractable ways. But the Bluesky application still conceals the data layer more than it exposes it, so I made a ruthlessly basic Bluesky query interface called SkyQ to try to invert this. You can see the data directly, and wander through it both curiously and computationally. You can build data tools for yourself, or for everyone, that everyone can share.
Current music streaming services, like Spotify, are not built this way at all. Your Spotify listening data is yours, morally, but so inaccessible to you that Spotify can make a yearly spectacle out of briefly sharing the most superficial and unverifiable analyses of it with you. And the collective knowledge that we, 600 million of us, amass through our listening, is so inaccessible to us that Spotify can passively deprive us of its insights just by not caring.
Curio, thus, my web thing for collating music curiosity, is both an experiment in making a music interface that does music things the way I personally want them done, but also a meta-experiment in making a data experience that uses your data with respect for your data rights. Every Curio page has data link at the bottom. Every bit of data Curio stores is also visible directly, on a query page where you can explore it however you like. I made a bunch of Spotify-Wrapped-like tools with which you can analyze your listening, but they do so with queries you can see, check, change or build upon, so if your goals diverge from mine, you are free to pursue them. The more paths we can follow, the more we will learn about how to reach anywhere.
There is a lot more to the human future of Data Rights than just microblogging and listening-history heatmaps, obviously. We are not yet near it, and we probably won't reach it with just our web browsers and a query language and a manifesto. Maybe no tendrils of these specific current dreams of mine will end up swirling in whatever collective dreams we eventually create by agreeing to share. I claim no certainty about the details. Certainty is not my goal. Possibility? Less resignation, more hope. I'm totally sure of almost nothing.
But I'm pretty sure we only get dreamier futures by dreaming.
You are entitled to both your public and private data. Your public data can be used by the public without your consent, but not without your awareness and their accountability. You are entitled to an intelligible and verifiable explanation of how it has been used. You are entitled to be able to double-check the sorting of your Spotify Wrapped just as you can double-check the math for the interest payments from your savings account.
You may choose to share your private data with other people, or applications, or corporations, in order to let them do something for you, or to help you do something for other people. For this your informed consent is necessary, and thus you are entitled to an intelligible and verifiable explanation of how your data would be used if you permit. You are entitled to know what Spotify would do with your Wrapped before you decide whether to join.
This is the world we have now:
you < corporations > software > your data
This is the world we want:
you > your data > software > corporations
The actors are the same, but the roles and the power are not. Today most computational power is structurally centralized and hoarded, and thus its potential for conversion into human energy is constrained and reduced. Most software is made by corporations, formulated for their corporate goals, and sealed against any other access or experimentation. Recent developments like LLM AIs seem inertially on a path towards even more centralized power-control and thus individual and social powerlessness.
We want a future, instead, in which creative power is widely distributed and human energy is bountifully amplified. We want software creation to be democratized so that our sources of imagination can be more broadly recruited. We want people and groups to have the power to pursue their own goals, not just for our own narrow sakes, but for our collective potential.
For this world to exist, we must figure out how, both logistically and politically, to move the data layer on which most meaningful software acts into the computational and conversational open. We need not just data portability -- the right to chose between evils -- but a shared language for talking about algorithms and data logic like we use math to discuss numbers. We need to be able to talk about what we want, and test what we might have and how.
This is how the AT Protocol, on which the social microblogging platform Bluesky runs, is designed. Its schemas are public, its public information is public. Bluesky, the application, makes use of this protocol and your data to construct a social experience for you and with you, producing feeds and following and public conversations and personal data ownership. The Bluesky software is open source, and most of the data relationships that constitute the social network are derivable from accessible data in tractable ways. But the Bluesky application still conceals the data layer more than it exposes it, so I made a ruthlessly basic Bluesky query interface called SkyQ to try to invert this. You can see the data directly, and wander through it both curiously and computationally. You can build data tools for yourself, or for everyone, that everyone can share.
Current music streaming services, like Spotify, are not built this way at all. Your Spotify listening data is yours, morally, but so inaccessible to you that Spotify can make a yearly spectacle out of briefly sharing the most superficial and unverifiable analyses of it with you. And the collective knowledge that we, 600 million of us, amass through our listening, is so inaccessible to us that Spotify can passively deprive us of its insights just by not caring.
Curio, thus, my web thing for collating music curiosity, is both an experiment in making a music interface that does music things the way I personally want them done, but also a meta-experiment in making a data experience that uses your data with respect for your data rights. Every Curio page has data link at the bottom. Every bit of data Curio stores is also visible directly, on a query page where you can explore it however you like. I made a bunch of Spotify-Wrapped-like tools with which you can analyze your listening, but they do so with queries you can see, check, change or build upon, so if your goals diverge from mine, you are free to pursue them. The more paths we can follow, the more we will learn about how to reach anywhere.
There is a lot more to the human future of Data Rights than just microblogging and listening-history heatmaps, obviously. We are not yet near it, and we probably won't reach it with just our web browsers and a query language and a manifesto. Maybe no tendrils of these specific current dreams of mine will end up swirling in whatever collective dreams we eventually create by agreeing to share. I claim no certainty about the details. Certainty is not my goal. Possibility? Less resignation, more hope. I'm totally sure of almost nothing.
But I'm pretty sure we only get dreamier futures by dreaming.
¶ Subgenres, subcontinents · 9 December 2024 essay/listen/tech


¶ Know Yourself (For Free) · 30 November 2024 listen/tech
It's that time of year when companies begin pretending that a) the year is already over, and b) you should be grateful to them for giving you a tiny yearly glimpse of your own data.
But your data is yours. You shouldn't have to elaborately ask for it, but that tends to be the state at the moment. You can get your streaming history from Spotify by going to Account > Security and privacy > Account privacy (of course). They're hoping you don't, because they really want you to eagerly wait for them to tell you what you listened to this year (not counting the last few weeks of it) in parsimoniously abbreviated detail and laboriously garish graphic design.
But if you do, because you can, and you get a Spotify API key, which you can, then you can play with Curio, my experimental app for organizing music curiosity. Curio does a potentially puzzling assortment of things that I like to do, but it also has a query language, so that neither of us is limited by what I already think I want.
And so, among other things, you can make your own Wrapped.
Request your data. When you get it, it'll be a zip file. Unzip it and you'll get a folder full of files. Go to the Curio query page. Hit the "Load more data" button and select all the downloaded files in that folder whose names start with "Streaming_History_Audio_". Curio will stitch them all back together for you. Now you have your listening history.
Of course, to make sense of your listening history, you would need a bit more data. But you could run this query:
listening history
:ts>=2024
:ms_played>=30000
|id=(...spotify_track_uri,([:]),split.split:@3)
|track info=(.id.other tracks)
:(.track info.album.release_date:>2024)
|date=(...ts,(T),split.split:@1)
Translated, that says:
- start with your whole listening history
- filter that to just the plays from 2024
- filter that to just the songs you played at least 30 seconds of
- perform some arcane shenanigans to extract the ID from the Spotify track URI
- use that ID to get the full track info from the Spotify API
- filter the list to just the tracks that were released in 2024, because to a music person that's what "year in music" means
- extract the date from the Spotify timestamp
Hit Enter to run that, and then type "2024 tracks full" in the query-name box to the right, and hit Enter there too.

Now you have the right data to start doing some analysis.
You could now, for example, run this query:
2024 tracks full
/artist=(.track info.artist:@1),song=(.track info.name),date
|points=(....count,sqrt....sqrt)
/artist,song
|points=(.of....points,total)
#rank=points
- take the 2024 tracks from the first query
- group them by artist, song name and date
- give each artist-song-date triplet the quad root of the number of times you played it that day (because I don't trust looping very much)
- group the artist-song-date triplets into artist-song pairs
- score the pairs by totaling their triplets
- sort and rank the pairs by points
You could save that one as "2024 songs scored". Notice that it doesn't end after 5, or even after 100.
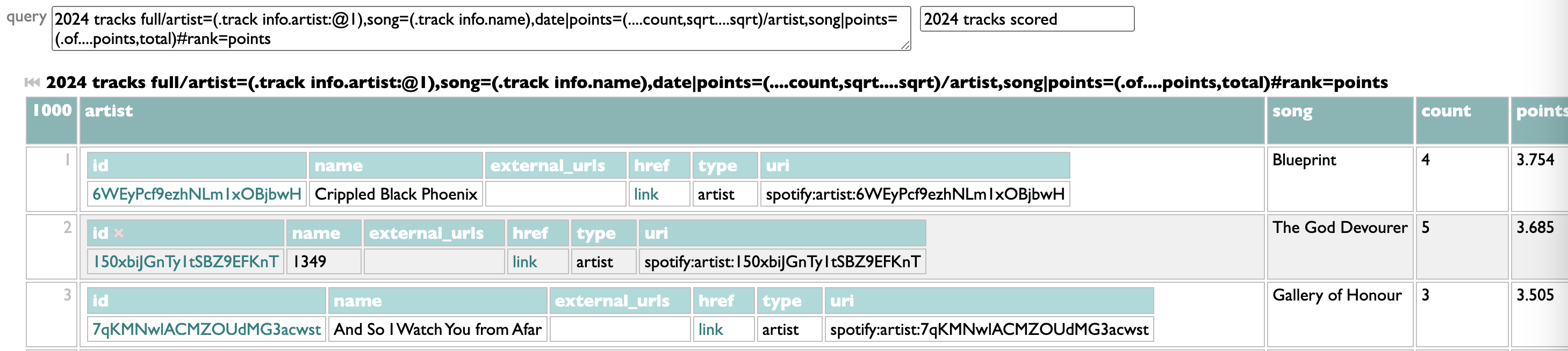
You could also do a very similar query for artists, just skipping the song part:
2024 tracks full
/artist=(.track info.artist),date
|points=(....count,sqrt)
/artist
|points=(.of....points,total)
#rank=points

And if you save that one as "2024 artists scored", then you could also use it for:
2024 artists scored
/genre=(.artist.artist genres.genres)
|points=(....count,sqrt....total),top artist=(.of:@1.name)#rank=points
and now you have a top genre list that isn't limited to 5, shows you artist counts and your top artist for each, and because this is all data, even lets you see which artists belong to every genre (click the "of[...]" link).
But those are just questions I asked. You can ask your own.
You should always be able to ask your own questions about yourself. You should demand to be.
But your data is yours. You shouldn't have to elaborately ask for it, but that tends to be the state at the moment. You can get your streaming history from Spotify by going to Account > Security and privacy > Account privacy (of course). They're hoping you don't, because they really want you to eagerly wait for them to tell you what you listened to this year (not counting the last few weeks of it) in parsimoniously abbreviated detail and laboriously garish graphic design.
But if you do, because you can, and you get a Spotify API key, which you can, then you can play with Curio, my experimental app for organizing music curiosity. Curio does a potentially puzzling assortment of things that I like to do, but it also has a query language, so that neither of us is limited by what I already think I want.
And so, among other things, you can make your own Wrapped.
Request your data. When you get it, it'll be a zip file. Unzip it and you'll get a folder full of files. Go to the Curio query page. Hit the "Load more data" button and select all the downloaded files in that folder whose names start with "Streaming_History_Audio_". Curio will stitch them all back together for you. Now you have your listening history.
Of course, to make sense of your listening history, you would need a bit more data. But you could run this query:
listening history
:ts>=2024
:ms_played>=30000
|id=(...spotify_track_uri,([:]),split.split:@3)
|track info=(.id.other tracks)
:(.track info.album.release_date:>2024)
|date=(...ts,(T),split.split:@1)
Translated, that says:
- start with your whole listening history
- filter that to just the plays from 2024
- filter that to just the songs you played at least 30 seconds of
- perform some arcane shenanigans to extract the ID from the Spotify track URI
- use that ID to get the full track info from the Spotify API
- filter the list to just the tracks that were released in 2024, because to a music person that's what "year in music" means
- extract the date from the Spotify timestamp
Hit Enter to run that, and then type "2024 tracks full" in the query-name box to the right, and hit Enter there too.
Now you have the right data to start doing some analysis.
You could now, for example, run this query:
2024 tracks full
/artist=(.track info.artist:@1),song=(.track info.name),date
|points=(....count,sqrt....sqrt)
/artist,song
|points=(.of....points,total)
#rank=points
- take the 2024 tracks from the first query
- group them by artist, song name and date
- give each artist-song-date triplet the quad root of the number of times you played it that day (because I don't trust looping very much)
- group the artist-song-date triplets into artist-song pairs
- score the pairs by totaling their triplets
- sort and rank the pairs by points
You could save that one as "2024 songs scored". Notice that it doesn't end after 5, or even after 100.
You could also do a very similar query for artists, just skipping the song part:
2024 tracks full
/artist=(.track info.artist),date
|points=(....count,sqrt)
/artist
|points=(.of....points,total)
#rank=points
And if you save that one as "2024 artists scored", then you could also use it for:
2024 artists scored
/genre=(.artist.artist genres.genres)
|points=(....count,sqrt....total),top artist=(.of:@1.name)#rank=points
and now you have a top genre list that isn't limited to 5, shows you artist counts and your top artist for each, and because this is all data, even lets you see which artists belong to every genre (click the "of[...]" link).
But those are just questions I asked. You can ask your own.
You should always be able to ask your own questions about yourself. You should demand to be.
¶ 6 November 2024
The next democracy we build will have to be better than this one.