
7 June 2013 to 27 February 2013
¶ Underneath the Noises · 7 June 2013 listen/tech
The Echo Nest company blog has a post from me today explaining a little more about the underpinnings and motivation behind Every Noise at Once.
¶ Noise Adjustments · 31 May 2013 listen/tech
Every Noise at Once began as a byproduct of some data experimentation I was doing at work at the Echo Nest, and although it has taken on something of its own life, as well, the underlying data experimentation continues, and I keep making new maps and plot to help myself think about how we can usefully describe music in numbers.
As I keep emphasizing, the map isn't a data visualization in a strict sense. But it does arise from scatter-plots. In the first versions, the axes went from electric (left) to acoustic (right), and from more sonic density (top) to more sonic spikiness (bottom). After a while I flipped these to be electric (top) to acoustic (bottom), and from more sonic density (left) to more sonic spikiness (right). Both of these worked pretty well, with obvious clusters of things we know are similar in the real world.
Both also had plenty of micro-level oddities. These are just 2 of the 10 dimensions in our actual analyses, and even with 10 dimensions we're not yet always able to distinguish conclusively between things that we as human listeners think of as patently distinct. And the data shifts daily, and the math that bumps things around so we can read them injects its own sort of erosional contours into the process. So things happen, like "intelligent dance music" ending up sandwiched between "southern soul" and "memphis soul". I don't really mind this. At least we got "southern soul" and "memphis soul" close to each other.
But I keep fiddling with the numbers, and with today's map update both axes are now using different calculations to try to get at the same basic ideas more accurately. Or more expressively, maybe.
The acoustic/electric axis (down to up) is now more of an organic/mechanical axis. This doesn't make much difference at the bottom, as the most acoustic forms also tend to be pretty organic. But if anybody comes up with a new genre of robots playing Michael Nyman soundtracks on dulcimers, we now ought to be able to distinguish it from bluegrass. And where the old acoustic/electric scale had both metal and techno forms across the very top, the new organic/mechanical scale recognizes that there's still a lot of organism in highly electrified metal, and reserves the top of the scale for house/techno/synthpop forms that are driven by both synthesized timbres and rhythms. Plus now "futurepop" is top center, and if our dreams of the future don't represent some kind of exaggerated caricature of the present, then what's the point?
The new left-right axis is, similarly, a new attempt to better express the same dense/spiky idea, which I've started describing to myself as "bounciness". At the far left, atmospheric metal and ambient/drone forms are definitively unbouncy, and at the far right, reggae- and hip-hop-derived forms are fine exemplars of what I mean by bouncy or spiky. I didn't know until one of my co-workers added it recently that "bounce" was a genre, and it scores highly on my new bounciness measure, so that's good.
Combine these two axis-changes and the result is that the top left corner of the map kind of rotates, squishily but with a certain arboreal elegance, 45 degrees counter-clockwise:


It's hard to imagine that anybody but me really cares about this, in itself. But I think it does a very slightly better overall job of genre-positioning, which is at least partially the point. So now "intelligent dance music" moves up towards chill-out and turntablism, a little farther from old souls. Surf music and experimental rock pull apart (surf up, experimental rock down). The dense and electric, but organic, stoner metal and sludge metal move down, and the similarly dense but more synthetic gothic metal and gothic symphonic metal move up, and the former no longer fall between the latter. Reggaeton moves up closer to moombahton.
Not that there aren't some new curiosities, too. Worship and grunge end up together, but "worship" is a culturally defined genre with a mishmash of musical styles, so it's likely to wander around a bit randomly in any audio-based map (it was next to british pop before). New age ends up between punk blues and garage rock in the new map, which probably is not a juxtraposition with exploratory value, but it was next to video game music before, so whatever. Schlager and breakcore is a similarly hilarious pairing, but in the cluster with german pop, turbo folk and k pop it kind of starts to make sense. Riot grrrl pulls away from the fringes of metal towards lo fi.
So there we are. Minor improvements, maybe. Some days that's what I accomplish. I like to think of it as craftsmanship. Because that definitely sounds better than "fidgeting".
PS: If you don't care about all this, but do care about discovering music, this update also adds the 60s French pop genre ye ye, the Brazilian dance styles pagode and forro, the Scottish traditional form pipe band, and the drum-and-bass variations liquid funk, glitch hop and wonky. And if you care about listening to music, this update also fixes a bug I hadn't noticed that caused only the most prominent bands in each genre to get clickable song-samples, so now all but the really obscure ones ought to have songs again.
As I keep emphasizing, the map isn't a data visualization in a strict sense. But it does arise from scatter-plots. In the first versions, the axes went from electric (left) to acoustic (right), and from more sonic density (top) to more sonic spikiness (bottom). After a while I flipped these to be electric (top) to acoustic (bottom), and from more sonic density (left) to more sonic spikiness (right). Both of these worked pretty well, with obvious clusters of things we know are similar in the real world.
Both also had plenty of micro-level oddities. These are just 2 of the 10 dimensions in our actual analyses, and even with 10 dimensions we're not yet always able to distinguish conclusively between things that we as human listeners think of as patently distinct. And the data shifts daily, and the math that bumps things around so we can read them injects its own sort of erosional contours into the process. So things happen, like "intelligent dance music" ending up sandwiched between "southern soul" and "memphis soul". I don't really mind this. At least we got "southern soul" and "memphis soul" close to each other.
But I keep fiddling with the numbers, and with today's map update both axes are now using different calculations to try to get at the same basic ideas more accurately. Or more expressively, maybe.
The acoustic/electric axis (down to up) is now more of an organic/mechanical axis. This doesn't make much difference at the bottom, as the most acoustic forms also tend to be pretty organic. But if anybody comes up with a new genre of robots playing Michael Nyman soundtracks on dulcimers, we now ought to be able to distinguish it from bluegrass. And where the old acoustic/electric scale had both metal and techno forms across the very top, the new organic/mechanical scale recognizes that there's still a lot of organism in highly electrified metal, and reserves the top of the scale for house/techno/synthpop forms that are driven by both synthesized timbres and rhythms. Plus now "futurepop" is top center, and if our dreams of the future don't represent some kind of exaggerated caricature of the present, then what's the point?
The new left-right axis is, similarly, a new attempt to better express the same dense/spiky idea, which I've started describing to myself as "bounciness". At the far left, atmospheric metal and ambient/drone forms are definitively unbouncy, and at the far right, reggae- and hip-hop-derived forms are fine exemplars of what I mean by bouncy or spiky. I didn't know until one of my co-workers added it recently that "bounce" was a genre, and it scores highly on my new bounciness measure, so that's good.
Combine these two axis-changes and the result is that the top left corner of the map kind of rotates, squishily but with a certain arboreal elegance, 45 degrees counter-clockwise:
It's hard to imagine that anybody but me really cares about this, in itself. But I think it does a very slightly better overall job of genre-positioning, which is at least partially the point. So now "intelligent dance music" moves up towards chill-out and turntablism, a little farther from old souls. Surf music and experimental rock pull apart (surf up, experimental rock down). The dense and electric, but organic, stoner metal and sludge metal move down, and the similarly dense but more synthetic gothic metal and gothic symphonic metal move up, and the former no longer fall between the latter. Reggaeton moves up closer to moombahton.
Not that there aren't some new curiosities, too. Worship and grunge end up together, but "worship" is a culturally defined genre with a mishmash of musical styles, so it's likely to wander around a bit randomly in any audio-based map (it was next to british pop before). New age ends up between punk blues and garage rock in the new map, which probably is not a juxtraposition with exploratory value, but it was next to video game music before, so whatever. Schlager and breakcore is a similarly hilarious pairing, but in the cluster with german pop, turbo folk and k pop it kind of starts to make sense. Riot grrrl pulls away from the fringes of metal towards lo fi.
So there we are. Minor improvements, maybe. Some days that's what I accomplish. I like to think of it as craftsmanship. Because that definitely sounds better than "fidgeting".
PS: If you don't care about all this, but do care about discovering music, this update also adds the 60s French pop genre ye ye, the Brazilian dance styles pagode and forro, the Scottish traditional form pipe band, and the drum-and-bass variations liquid funk, glitch hop and wonky. And if you care about listening to music, this update also fixes a bug I hadn't noticed that caused only the most prominent bands in each genre to get clickable song-samples, so now all but the really obscure ones ought to have songs again.
¶ Chorus of Noises · 27 May 2013 listen/tech
Some notes and discussions in various places about my genre-mapping experiment:
- LIG (Life Is Good Design, Tokyo) blog (via Google Translate)
- Der Kraftfuttermischwerk and followup here and here (all via Google Translate)
- Shades of Graceland (post)
- Bullseye with Jesse Thorn: Mark Frauenfelder's All-Time Favorites: The Hunter by Richard Stark and Every Noise At Once (audio)
- Echo Nest company blog-post about the Bullseye piece above
- MakeUseOf: Discover New Music By Mapping Musical Genres & Artists
- The Story Arcade
- Strangeways: A Map of Musical Genres!
- Sidespin: Put On Your Ear Goggles
- Newsring (France): Mozart, Miles Davis, The Beatles ... The musical geniuses have they been surpassed? (via Google Translate)
- Slate (France): Do You Know All the Musical Genres of the World? (via Google Translate)
- Huffington Post (France): "Every Noise At Once", all genres listed in an interactive infographic (via Google Translate)
- Konbini: Every Noise at Once, an Interactive Music Genres Map
- Freshness: Discovering Music Through Genre Maps
- Sampleface: A Clickable Music Genre Map
- Gizmodo: Possibly the Best Music Discovery System Yet
- Boing Boing: Clickable Musical Genre Map
- The Daily Swarm: This Tool Neatly Explains What All Those Genres Actually Mean
- Turn the Record Over: Listen to Almost Every Music Genre Via This Interactive Map
- The Journal of Music
- Animal: Finally Understand the Difference Between Dance Rock and Synthpop
- Information Is Beautiful Awards
- FastCompany Co.CREATE: Music Map Reveals What "Melodic Death Metal" and Every Other Genre Actually Sound Like
- Metafilter: The map of music
- Quomodocumque (post and discussion)
- I Love Music: Mapping All Music
The last one was instigated by me, and I participated in the Quomodocumque discussion, but I had nothing to do with the others.
Or look for more on Twitter or Google+...
PS: Recent additions include moombahton, c-pop, chinese traditional, chinese indie rock, post-disco, baroque, romantic, classical period, serialism, neue deutsche welle, tekno, gamelan, old-time, tin pan alley and classic garage rock, and improvements to garage rock (which is the modern revival version), death metal and opera.
I also made some tweaks to the artist-mapping code within genres to cut down on spurious outliers a little, and am trying some hopefully-improved logic for picking the example songs for each genre. And I put a "find artist" widget on the front page, which will tell you which genres that artist is in. Keep in mind that I only show a couple hundred representative artists for each genre, so plenty of bands that we would all agree "are" a certain genre won't actually appear in the maps here.
You can also now go from an artist to their Rdio page. The "related artists" on Rdio come from the same Echo Nest data that powers the genre maps, so this lets you keep exploring more or less indefinitely.
And I created a Twitter account for @EveryNoise, which I'll use for minor news and updates, rather than posting every one of them here.
- LIG (Life Is Good Design, Tokyo) blog (via Google Translate)
- Der Kraftfuttermischwerk and followup here and here (all via Google Translate)
- Shades of Graceland (post)
- Bullseye with Jesse Thorn: Mark Frauenfelder's All-Time Favorites: The Hunter by Richard Stark and Every Noise At Once (audio)
- Echo Nest company blog-post about the Bullseye piece above
- MakeUseOf: Discover New Music By Mapping Musical Genres & Artists
- The Story Arcade
- Strangeways: A Map of Musical Genres!
- Sidespin: Put On Your Ear Goggles
- Newsring (France): Mozart, Miles Davis, The Beatles ... The musical geniuses have they been surpassed? (via Google Translate)
- Slate (France): Do You Know All the Musical Genres of the World? (via Google Translate)
- Huffington Post (France): "Every Noise At Once", all genres listed in an interactive infographic (via Google Translate)
- Konbini: Every Noise at Once, an Interactive Music Genres Map
- Freshness: Discovering Music Through Genre Maps
- Sampleface: A Clickable Music Genre Map
- Gizmodo: Possibly the Best Music Discovery System Yet
- Boing Boing: Clickable Musical Genre Map
- The Daily Swarm: This Tool Neatly Explains What All Those Genres Actually Mean
- Turn the Record Over: Listen to Almost Every Music Genre Via This Interactive Map
- The Journal of Music
- Animal: Finally Understand the Difference Between Dance Rock and Synthpop
- Information Is Beautiful Awards
- FastCompany Co.CREATE: Music Map Reveals What "Melodic Death Metal" and Every Other Genre Actually Sound Like
- Metafilter: The map of music
- Quomodocumque (post and discussion)
- I Love Music: Mapping All Music
The last one was instigated by me, and I participated in the Quomodocumque discussion, but I had nothing to do with the others.
Or look for more on Twitter or Google+...
PS: Recent additions include moombahton, c-pop, chinese traditional, chinese indie rock, post-disco, baroque, romantic, classical period, serialism, neue deutsche welle, tekno, gamelan, old-time, tin pan alley and classic garage rock, and improvements to garage rock (which is the modern revival version), death metal and opera.
I also made some tweaks to the artist-mapping code within genres to cut down on spurious outliers a little, and am trying some hopefully-improved logic for picking the example songs for each genre. And I put a "find artist" widget on the front page, which will tell you which genres that artist is in. Keep in mind that I only show a couple hundred representative artists for each genre, so plenty of bands that we would all agree "are" a certain genre won't actually appear in the maps here.
You can also now go from an artist to their Rdio page. The "related artists" on Rdio come from the same Echo Nest data that powers the genre maps, so this lets you keep exploring more or less indefinitely.
And I created a Twitter account for @EveryNoise, which I'll use for minor news and updates, rather than posting every one of them here.
¶ Noisechasing · 26 April 2013 listen/tech
I keep working on the systems from which I derive Every Noise at Once, and update it periodically. It should now be doing a slightly better job than before at picking example songs, like Jimmy Eat World instead of My Chemical Romance for emo, Ornette Coleman instead of Miles Davis for avant-garde jazz, and hopefully etcetera.
We also keep adding genres, the most recent of which are qawwali, steampunk, warm drone, japanese psychedelic, microhouse, bounce, indian pop and electro swing. If you are thinking of inventing a new style of music, please check and see if there are already 241 bands from Slovenia and Malawi fighting over its protocols and implications.

We also keep adding genres, the most recent of which are qawwali, steampunk, warm drone, japanese psychedelic, microhouse, bounce, indian pop and electro swing. If you are thinking of inventing a new style of music, please check and see if there are already 241 bands from Slovenia and Malawi fighting over its protocols and implications.
¶ Scott Miller, 1960-2013 · 18 April 2013
I try to think of words for this inconceivable day, and fail. Better, maybe, to stick with words for more conceivable days, instead.
The roads from "Sleeping Through Heaven" to "720 Times Happier Than the Unjust Man", from "In a Delorean" to "No One's Watching My Limo Ride", from "Too Late for Tears" to "Blackness, Blackness", do not end here. And if it is days before he returns to them, or years, we have this triumphantly hopeless farewell to keep us company. Patience will be painless, and the days of waiting serene.
TWAS 87: All Advice Is Ways of Saying "Let It Go"
TWAS 88: The Excuses, Then the Outcomes, Then the Cause
TWAS 177: Expensive Breathing
TWAS 273: No One Calls But to Weigh In Against Us
And also
Throwing the Election
You had my vote. And not just mine. And whatever else you lived with, I so wish they could have been enough.
The roads from "Sleeping Through Heaven" to "720 Times Happier Than the Unjust Man", from "In a Delorean" to "No One's Watching My Limo Ride", from "Too Late for Tears" to "Blackness, Blackness", do not end here. And if it is days before he returns to them, or years, we have this triumphantly hopeless farewell to keep us company. Patience will be painless, and the days of waiting serene.
TWAS 87: All Advice Is Ways of Saying "Let It Go"
TWAS 88: The Excuses, Then the Outcomes, Then the Cause
TWAS 177: Expensive Breathing
TWAS 273: No One Calls But to Weigh In Against Us
And also
Throwing the Election
You had my vote. And not just mine. And whatever else you lived with, I so wish they could have been enough.
¶ Tuesday's Alive · 9 April 2013 listen/tech
Remember, in the old days, how we would go to the record store on Tuesdays, when new releases came out? That was fun.
New releases still come out on Tuesdays, in the US, but the thing about flipping through the New Release bin at a good record store was that you could do it. There were dozens of new releases in the bin, and you could look through dozens in a couple minutes. In the new music-world, there are thousands of new releases. "Looking through them" takes forever, and many many many of them are things your record store wouldn't have put in the bin. Many of them are things your record store wouldn't even have ordered.
But the new world is supposed to be better than the old world, isn't that the point? So here's a little piece of my ongoing effort to help make it so:
Rdio New Releases by Genre
This takes all the things Rdio says are new this week and categorizes them, occasionally over-enthusiastically, by genre. Your record store didn't have the time or space to do this, but now we can.
Obviously this would be better if you could see only the genres you care about, and better still if the computers could figure out which ones those are automatically. But for now, it's just an HTML page. See if it helps you discover anything.
New releases still come out on Tuesdays, in the US, but the thing about flipping through the New Release bin at a good record store was that you could do it. There were dozens of new releases in the bin, and you could look through dozens in a couple minutes. In the new music-world, there are thousands of new releases. "Looking through them" takes forever, and many many many of them are things your record store wouldn't have put in the bin. Many of them are things your record store wouldn't even have ordered.
But the new world is supposed to be better than the old world, isn't that the point? So here's a little piece of my ongoing effort to help make it so:
Rdio New Releases by Genre
This takes all the things Rdio says are new this week and categorizes them, occasionally over-enthusiastically, by genre. Your record store didn't have the time or space to do this, but now we can.
Obviously this would be better if you could see only the genres you care about, and better still if the computers could figure out which ones those are automatically. But for now, it's just an HTML page. See if it helps you discover anything.
¶ Every Noise at Once · 8 April 2013 listen/tech
I started making pictures of the music-genre space for diagnostic purposes at work. The exercise keeps threatening to take on a life of its own, but then each new thing turns out to have some functional purpose after all. Which leads to some other analytical feature, which leads to yet another interesting by-product.
This latest not-so-analytical version here adds a whole new level, literally. If you hover over, or click, any genre in the main map, you'll see a » link. Click that to see an artist-level map of that genre, complete with representative audio for each artist and a genre-specific car-radio scanner.
In addition, I've now made auto-generated introductory playlists for each genre on Rdio, and there are links to these at the bottom of the individual genre maps. Rdio's "related artists" come from the same underlying Echo Nest data and processes that drive these genres and their maps, so between these pictures, the Rdio intro playlists, and Rdio related artists from the artists of the songs on those playlists, there's the rough, erratic beginnings of an exploratory path that can lead you from an of-course-inadequate attempt at a overview of all music into at least a representative subset of its component songs. The intro playlists alone add up to about a complete calendar-year of music, which I think says as much as anything about the relationship between humanity and music.
People keep asking me, very reasonably, what the "axes" are on these things. They aren't exactly data plots, due to the cheerfully aggressive algorithmic rearranging of names to make them readable. But roughly speaking, left is more electric and right is more acoustic. And even more roughly speaking, up is more sonic density or uniformity, down is more sonic spareness or spikiness. The less data, the looser the correlations, so the artist distribution within a genre tends to be necessarily less precisely data-related than the distribution of genres. And the genre views are normalized individually, so the bands at the right edge of pagan black metal are actually far less acoustic than those at the right edge of warm drone. If you really want to worry about dimensional distributions and standard deviations, you should come work at the Echo Nest. Otherwise, just focus on the juxtapositions and clusters, and make up your own mind whether they help you think about anything.
Also, lest you think my "Every Noise at Once" title is idle, note that if you alt-click to open different genres in different browser tabs you can turn on lots of scanners at once. I'm not advocating this, exactly, but it is a thing that you can do.

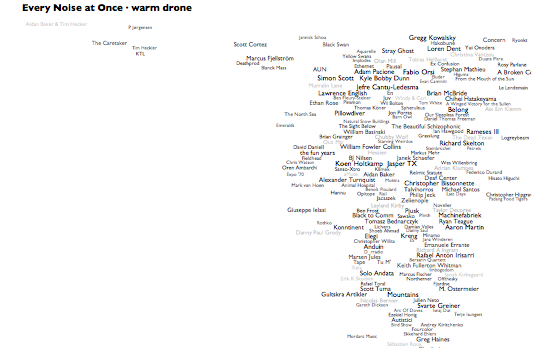

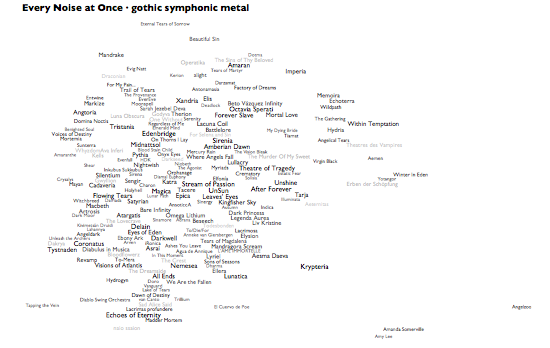
This latest not-so-analytical version here adds a whole new level, literally. If you hover over, or click, any genre in the main map, you'll see a » link. Click that to see an artist-level map of that genre, complete with representative audio for each artist and a genre-specific car-radio scanner.
In addition, I've now made auto-generated introductory playlists for each genre on Rdio, and there are links to these at the bottom of the individual genre maps. Rdio's "related artists" come from the same underlying Echo Nest data and processes that drive these genres and their maps, so between these pictures, the Rdio intro playlists, and Rdio related artists from the artists of the songs on those playlists, there's the rough, erratic beginnings of an exploratory path that can lead you from an of-course-inadequate attempt at a overview of all music into at least a representative subset of its component songs. The intro playlists alone add up to about a complete calendar-year of music, which I think says as much as anything about the relationship between humanity and music.
People keep asking me, very reasonably, what the "axes" are on these things. They aren't exactly data plots, due to the cheerfully aggressive algorithmic rearranging of names to make them readable. But roughly speaking, left is more electric and right is more acoustic. And even more roughly speaking, up is more sonic density or uniformity, down is more sonic spareness or spikiness. The less data, the looser the correlations, so the artist distribution within a genre tends to be necessarily less precisely data-related than the distribution of genres. And the genre views are normalized individually, so the bands at the right edge of pagan black metal are actually far less acoustic than those at the right edge of warm drone. If you really want to worry about dimensional distributions and standard deviations, you should come work at the Echo Nest. Otherwise, just focus on the juxtapositions and clusters, and make up your own mind whether they help you think about anything.
Also, lest you think my "Every Noise at Once" title is idle, note that if you alt-click to open different genres in different browser tabs you can turn on lots of scanners at once. I'm not advocating this, exactly, but it is a thing that you can do.
¶ A Better Picture of Every Noise at Once · 22 March 2013
I've been periodically experimenting with other tools for generating bubble-chart pictures of the music-genre space, and after tweaking and cajoling and giving up on several tools it finally occurred to me that maybe the thing I didn't like about my bubble-charts was the bubbles.
And the other obvious wrong thing was that it was just a picture. So here's a new version that is more legible (albeit not necessarily more intelligible), and in which you can hear examples of each genre by clicking on them.

Yes, that's better.
[The audio requires a modern browser like Safari or Chrome...]
[Updated 3/29 with yet another rearrangement.]
[Updated 4/1 with a "scan" feature. Like the whole planet is your car-radio.]
And the other obvious wrong thing was that it was just a picture. So here's a new version that is more legible (albeit not necessarily more intelligible), and in which you can hear examples of each genre by clicking on them.
Yes, that's better.
[The audio requires a modern browser like Safari or Chrome...]
[Updated 3/29 with yet another rearrangement.]
[Updated 4/1 with a "scan" feature. Like the whole planet is your car-radio.]
¶ Pictures of Every Noise at Once · 27 February 2013
At work today I found myself making pictures. I should probably get a better tool for making these, so they could be huge and interactive and more intelligible, but there's also something very fitting about this chaotic, overlapping state. Click to see them just barely big enough to read. The third one is actually the biggest and most readable at full size.
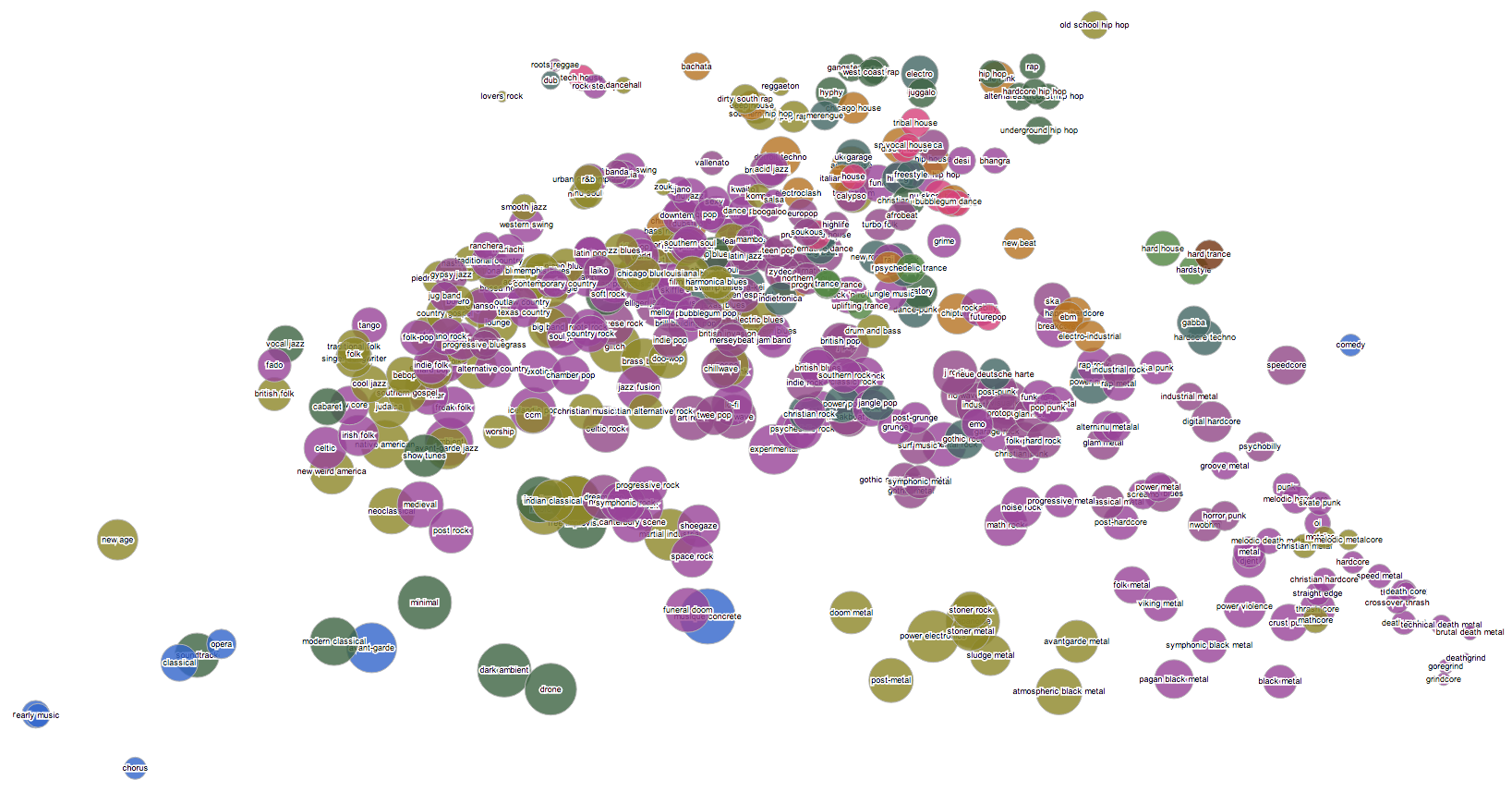


[Update: several people have asked me, very reasonably, what the axes and dimensions are in these. Although there are answers, technically, I think that's not really the point here. These pictures are interesting to me precisely without legends and units and grid lines. They are not explanations, they are questions. Are there elements of your experience of music that map to what you see here? Do the things you like, or don't like, cluster or align? Is this a picture of our world, or something else?]
[Update: several people have asked me, very reasonably, what the axes and dimensions are in these. Although there are answers, technically, I think that's not really the point here. These pictures are interesting to me precisely without legends and units and grid lines. They are not explanations, they are questions. Are there elements of your experience of music that map to what you see here? Do the things you like, or don't like, cluster or align? Is this a picture of our world, or something else?]