
18 April 2013 to 28 January 2013
¶ Scott Miller, 1960-2013 · 18 April 2013
I try to think of words for this inconceivable day, and fail. Better, maybe, to stick with words for more conceivable days, instead.
The roads from "Sleeping Through Heaven" to "720 Times Happier Than the Unjust Man", from "In a Delorean" to "No One's Watching My Limo Ride", from "Too Late for Tears" to "Blackness, Blackness", do not end here. And if it is days before he returns to them, or years, we have this triumphantly hopeless farewell to keep us company. Patience will be painless, and the days of waiting serene.
TWAS 87: All Advice Is Ways of Saying "Let It Go"
TWAS 88: The Excuses, Then the Outcomes, Then the Cause
TWAS 177: Expensive Breathing
TWAS 273: No One Calls But to Weigh In Against Us
And also
Throwing the Election
You had my vote. And not just mine. And whatever else you lived with, I so wish they could have been enough.
The roads from "Sleeping Through Heaven" to "720 Times Happier Than the Unjust Man", from "In a Delorean" to "No One's Watching My Limo Ride", from "Too Late for Tears" to "Blackness, Blackness", do not end here. And if it is days before he returns to them, or years, we have this triumphantly hopeless farewell to keep us company. Patience will be painless, and the days of waiting serene.
TWAS 87: All Advice Is Ways of Saying "Let It Go"
TWAS 88: The Excuses, Then the Outcomes, Then the Cause
TWAS 177: Expensive Breathing
TWAS 273: No One Calls But to Weigh In Against Us
And also
Throwing the Election
You had my vote. And not just mine. And whatever else you lived with, I so wish they could have been enough.
¶ Tuesday's Alive · 9 April 2013 listen/tech
Remember, in the old days, how we would go to the record store on Tuesdays, when new releases came out? That was fun.
New releases still come out on Tuesdays, in the US, but the thing about flipping through the New Release bin at a good record store was that you could do it. There were dozens of new releases in the bin, and you could look through dozens in a couple minutes. In the new music-world, there are thousands of new releases. "Looking through them" takes forever, and many many many of them are things your record store wouldn't have put in the bin. Many of them are things your record store wouldn't even have ordered.
But the new world is supposed to be better than the old world, isn't that the point? So here's a little piece of my ongoing effort to help make it so:
Rdio New Releases by Genre
This takes all the things Rdio says are new this week and categorizes them, occasionally over-enthusiastically, by genre. Your record store didn't have the time or space to do this, but now we can.
Obviously this would be better if you could see only the genres you care about, and better still if the computers could figure out which ones those are automatically. But for now, it's just an HTML page. See if it helps you discover anything.
New releases still come out on Tuesdays, in the US, but the thing about flipping through the New Release bin at a good record store was that you could do it. There were dozens of new releases in the bin, and you could look through dozens in a couple minutes. In the new music-world, there are thousands of new releases. "Looking through them" takes forever, and many many many of them are things your record store wouldn't have put in the bin. Many of them are things your record store wouldn't even have ordered.
But the new world is supposed to be better than the old world, isn't that the point? So here's a little piece of my ongoing effort to help make it so:
Rdio New Releases by Genre
This takes all the things Rdio says are new this week and categorizes them, occasionally over-enthusiastically, by genre. Your record store didn't have the time or space to do this, but now we can.
Obviously this would be better if you could see only the genres you care about, and better still if the computers could figure out which ones those are automatically. But for now, it's just an HTML page. See if it helps you discover anything.
¶ Every Noise at Once · 8 April 2013 listen/tech
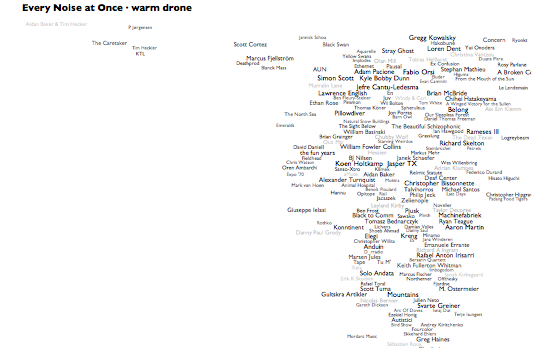
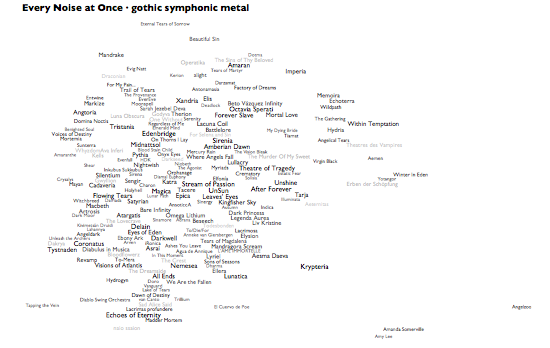
I started making pictures of the music-genre space for diagnostic purposes at work. The exercise keeps threatening to take on a life of its own, but then each new thing turns out to have some functional purpose after all. Which leads to some other analytical feature, which leads to yet another interesting by-product.
This latest not-so-analytical version here adds a whole new level, literally. If you hover over, or click, any genre in the main map, you'll see a » link. Click that to see an artist-level map of that genre, complete with representative audio for each artist and a genre-specific car-radio scanner.
In addition, I've now made auto-generated introductory playlists for each genre on Rdio, and there are links to these at the bottom of the individual genre maps. Rdio's "related artists" come from the same underlying Echo Nest data and processes that drive these genres and their maps, so between these pictures, the Rdio intro playlists, and Rdio related artists from the artists of the songs on those playlists, there's the rough, erratic beginnings of an exploratory path that can lead you from an of-course-inadequate attempt at a overview of all music into at least a representative subset of its component songs. The intro playlists alone add up to about a complete calendar-year of music, which I think says as much as anything about the relationship between humanity and music.
People keep asking me, very reasonably, what the "axes" are on these things. They aren't exactly data plots, due to the cheerfully aggressive algorithmic rearranging of names to make them readable. But roughly speaking, left is more electric and right is more acoustic. And even more roughly speaking, up is more sonic density or uniformity, down is more sonic spareness or spikiness. The less data, the looser the correlations, so the artist distribution within a genre tends to be necessarily less precisely data-related than the distribution of genres. And the genre views are normalized individually, so the bands at the right edge of pagan black metal are actually far less acoustic than those at the right edge of warm drone. If you really want to worry about dimensional distributions and standard deviations, you should come work at the Echo Nest. Otherwise, just focus on the juxtapositions and clusters, and make up your own mind whether they help you think about anything.
Also, lest you think my "Every Noise at Once" title is idle, note that if you alt-click to open different genres in different browser tabs you can turn on lots of scanners at once. I'm not advocating this, exactly, but it is a thing that you can do.


This latest not-so-analytical version here adds a whole new level, literally. If you hover over, or click, any genre in the main map, you'll see a » link. Click that to see an artist-level map of that genre, complete with representative audio for each artist and a genre-specific car-radio scanner.
In addition, I've now made auto-generated introductory playlists for each genre on Rdio, and there are links to these at the bottom of the individual genre maps. Rdio's "related artists" come from the same underlying Echo Nest data and processes that drive these genres and their maps, so between these pictures, the Rdio intro playlists, and Rdio related artists from the artists of the songs on those playlists, there's the rough, erratic beginnings of an exploratory path that can lead you from an of-course-inadequate attempt at a overview of all music into at least a representative subset of its component songs. The intro playlists alone add up to about a complete calendar-year of music, which I think says as much as anything about the relationship between humanity and music.
People keep asking me, very reasonably, what the "axes" are on these things. They aren't exactly data plots, due to the cheerfully aggressive algorithmic rearranging of names to make them readable. But roughly speaking, left is more electric and right is more acoustic. And even more roughly speaking, up is more sonic density or uniformity, down is more sonic spareness or spikiness. The less data, the looser the correlations, so the artist distribution within a genre tends to be necessarily less precisely data-related than the distribution of genres. And the genre views are normalized individually, so the bands at the right edge of pagan black metal are actually far less acoustic than those at the right edge of warm drone. If you really want to worry about dimensional distributions and standard deviations, you should come work at the Echo Nest. Otherwise, just focus on the juxtapositions and clusters, and make up your own mind whether they help you think about anything.
Also, lest you think my "Every Noise at Once" title is idle, note that if you alt-click to open different genres in different browser tabs you can turn on lots of scanners at once. I'm not advocating this, exactly, but it is a thing that you can do.
¶ A Better Picture of Every Noise at Once · 22 March 2013
I've been periodically experimenting with other tools for generating bubble-chart pictures of the music-genre space, and after tweaking and cajoling and giving up on several tools it finally occurred to me that maybe the thing I didn't like about my bubble-charts was the bubbles.
And the other obvious wrong thing was that it was just a picture. So here's a new version that is more legible (albeit not necessarily more intelligible), and in which you can hear examples of each genre by clicking on them.

Yes, that's better.
[The audio requires a modern browser like Safari or Chrome...]
[Updated 3/29 with yet another rearrangement.]
[Updated 4/1 with a "scan" feature. Like the whole planet is your car-radio.]
And the other obvious wrong thing was that it was just a picture. So here's a new version that is more legible (albeit not necessarily more intelligible), and in which you can hear examples of each genre by clicking on them.
Yes, that's better.
[The audio requires a modern browser like Safari or Chrome...]
[Updated 3/29 with yet another rearrangement.]
[Updated 4/1 with a "scan" feature. Like the whole planet is your car-radio.]
¶ Pictures of Every Noise at Once · 27 February 2013
At work today I found myself making pictures. I should probably get a better tool for making these, so they could be huge and interactive and more intelligible, but there's also something very fitting about this chaotic, overlapping state. Click to see them just barely big enough to read. The third one is actually the biggest and most readable at full size.
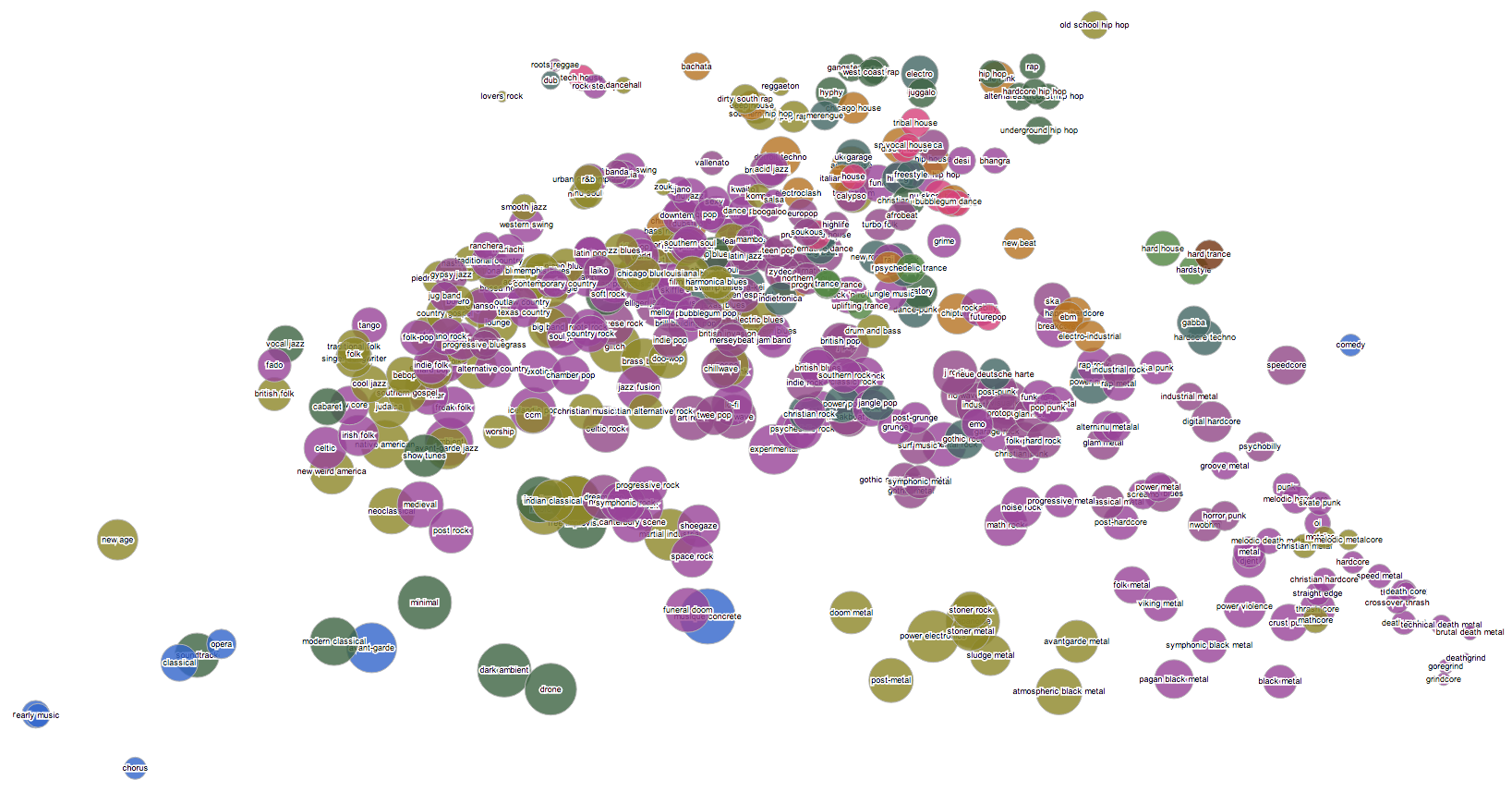


[Update: several people have asked me, very reasonably, what the axes and dimensions are in these. Although there are answers, technically, I think that's not really the point here. These pictures are interesting to me precisely without legends and units and grid lines. They are not explanations, they are questions. Are there elements of your experience of music that map to what you see here? Do the things you like, or don't like, cluster or align? Is this a picture of our world, or something else?]
[Update: several people have asked me, very reasonably, what the axes and dimensions are in these. Although there are answers, technically, I think that's not really the point here. These pictures are interesting to me precisely without legends and units and grid lines. They are not explanations, they are questions. Are there elements of your experience of music that map to what you see here? Do the things you like, or don't like, cluster or align? Is this a picture of our world, or something else?]
I needed some Europop this morning. Maybe you do, too. My robots found us some.
Measure my uncertainty about the current function of writing-about-music by noting that although I finalized my 2012 music list by the end of the year, it took me almost two months to get around to even an oblique annotation of it. But here it is:
2012: A Year in a Day
Abridged and unannotated versions are also available:
2012: A Year in a Day
Abridged and unannotated versions are also available:
When a storm approaches, make sure you have sufficient essential supplies: coffee, cereal, soup, the ingredients for making pancake batter from scratch, cats, enough paper to fold a card and an airplane for every person you know, strobe lights, a 5-hour playlist that eventually evolves from frenetic drum & bass into whatever you hope to feel after all of this is done.
At work I have this thing where you can pick any band and pull on the strands that connect them to the rest of the universe of music. This is what happened the other day when I wanted to see where the excellent new Kate Boy song "Northern Lights" took me. Bits of fragile atmospheric sparkly electronica started glittering out and there kind of doesn't seem to be any way to make them stop.
I basically do this kind of thing on and off most work days, and yet nearly every time, even with bands I found this way to begin with, I end up with dozens more interesting songs by bands that I'd never even encountered. I don't think the code is creating the bands out of nothing by its very invocation, but if I hadn't written the code I don't think I'd be so sure.
I basically do this kind of thing on and off most work days, and yet nearly every time, even with bands I found this way to begin with, I end up with dozens more interesting songs by bands that I'd never even encountered. I don't think the code is creating the bands out of nothing by its very invocation, but if I hadn't written the code I don't think I'd be so sure.