
¶ Query geekery motivated by music geekery · 27 January 2025 listen/tech
The listening-history tools in Curio include a thing for telling you the top genres from your listening year, because I think that's interesting.
Counting genres with Dactal, the query language in Curio, is easy. Or, at least, counting them in the simplest way is easy:
Take the list of artists (in this case the artists whose new 2024 songs you listened to in 2024), group them by genre, sort the genres by count.

Artists can and often do belong to multiple genres, though, so you might reasonably guess that some these overlap: symphonic metal and symphonic power metal; anime, j-rock, alt-idol, idol rock?
One very simple algorithm for reducing a set of overlapping categories to a smaller representative set is to take the genre with the most artists, then remove all the artists with that genre (whether they have other genres or not), then repeat. Dactal has a repeat operator for doing this kind of thing. We need a few other query features to make the query we need, but it's still fairly simple:
? is the Dactal start operator, which is implied at the beginning of a query and thus often doesn't actually appear at all, but here we use it to effectively interleave queries that keep track of the genres we've found and the artists we have left. We begin with all the artists and no genres, and then the indented subquery does two things:
- remove the artists from the last genre, using the set disjunction filter :-~~ (which does nothing the first time, because there are no genres yet)
- find the top genre for the artists we have left and add it to the existing list of topgenres
The ! repeat operator at the end of the subquery tells it to repeat the previous operation until it produces the same result twice (meaning there's nothing left to add), which happens for me after 139 iterations:

This is a little better. Flipping back and forth, I see that j-rock was 5th in the raw version, with 62 artists, but in the iterative version it drops to 13th, because only 36 of those 62 artists aren't part of any higher-ranked genres. Similarly, symphonic power metal drops from 6th to 12th. Japanese alternative rock moves up, because only 1 of those 56 artists was being double-counted before.
Really, though, this list of 139 "representative" genres still overstates the granularity into which my listening is emotionally organized. If you do not tend to use the words "granularity" and "emotionally" in the same sentences in your internal monologue, then you should probably cut your losses and tune out now. In order to cluster genres instead of just subsetting them, we need almost every major feature of Dactal:
I'm not going to claim this is "easy", but I've written variations on this algorithm in Ruby, Python, SQL and Javascript over the years, and I can tell you that all of those versions were much longer and involved way more punctuation than this, in addition to a lot more words that are about computers instead of about music.
The first two steps of the clustering are about the same as in the simpler version: eliminate any artists we've already used, and then find the top genre. Here we're scoring genres by summing up the square roots of artist points, instead of just counting artists, to measure a combination of listening breadth and listening depth, but that's added complexity in the question, not just the answer.
The clustering part is that once we have a top genre, we take all its artists and count their other genres, and then compare the overlap sizes with those genres' total artist counts (using lookups in the genre index created in the second line of the query). Other genres that overlap non-trivially with the first genre also get added to the cluster. Then the whole thing repeats. So instead of building a flat list of genres, this version builds a list of nested genre lists.
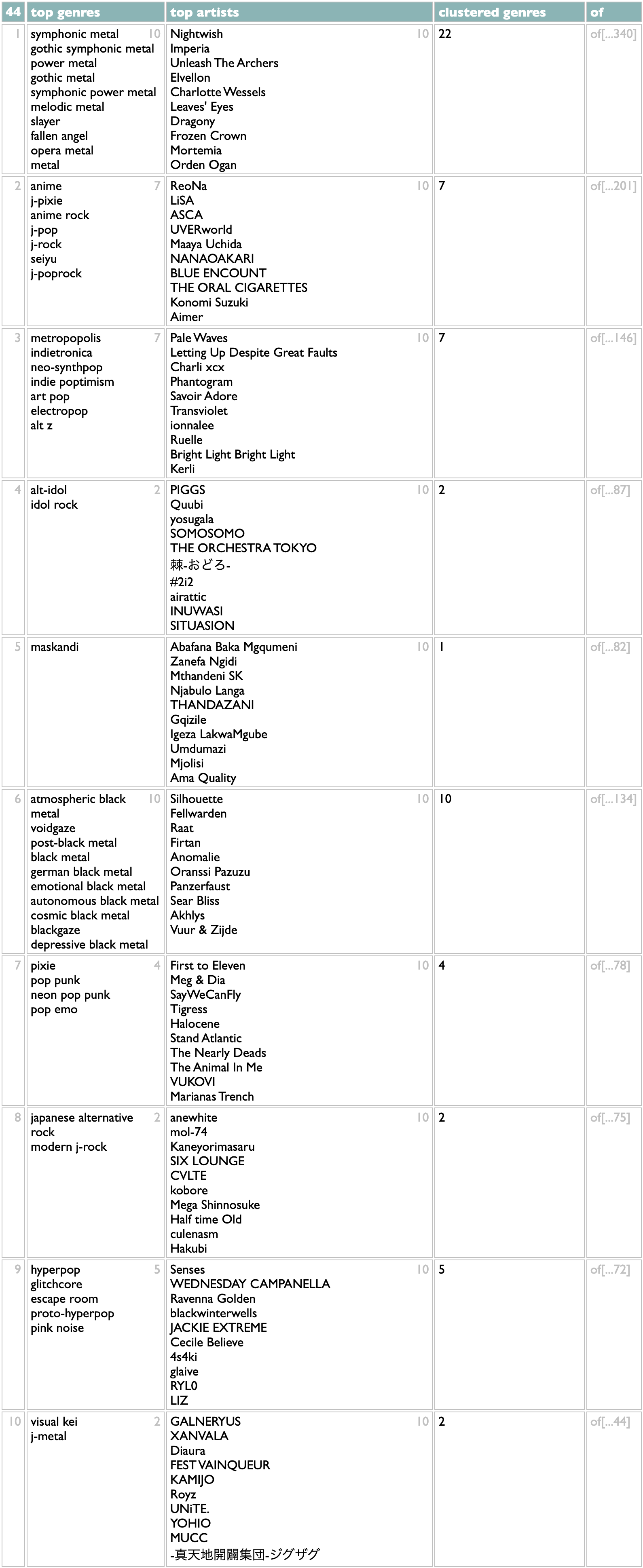
This is, for me, a lot closer to correct than the flat list, and certainly more interesting. It doesn't distribute my Japanese tastes exactly right (I don't care about anime, per se, so I usually put ReoNa and LiSA with the alt-idol groups for sonic reasons), but these first 10 statistical clusters are all aspects of my taste that I would list individually if you inadvisedly gave me an excuse, and of the 44 ways it breaks down my 2024, the only ones that get me thinking about override mechanics are towards the bottom where the genre data doesn't know that I tend to put the Spanish metal bands and the medieval rock nerds in with the other melodic metal styles.
If you want to try this on your own listening, there are now both "genres" and "genre clusters" views on the History page in Curio. But as with all of those, there is also a "see the query for this" at the bottom of the results, so if you want to experiment with variations, you can.
Although by you, as usual, I probably mean me. But by me I mean all of us.
Counting genres with Dactal, the query language in Curio, is easy. Or, at least, counting them in the simplest way is easy:
2024 artists scored/genre=(.artist.artist genres.genres)#count
Take the list of artists (in this case the artists whose new 2024 songs you listened to in 2024), group them by genre, sort the genres by count.
Artists can and often do belong to multiple genres, though, so you might reasonably guess that some these overlap: symphonic metal and symphonic power metal; anime, j-rock, alt-idol, idol rock?
One very simple algorithm for reducing a set of overlapping categories to a smaller representative set is to take the genre with the most artists, then remove all the artists with that genre (whether they have other genres or not), then repeat. Dactal has a repeat operator for doing this kind of thing. We need a few other query features to make the query we need, but it's still fairly simple:
artistsx=(2024 artists scored|genre=(.id.artist genres.genres))
?topgenres=()
?(
?artistsx=(artistsx:-~~(topgenres:@@1.of))
?topgenres=(topgenres,(artistsx/genre:count>=5#count:@1))
)!
?topgenres=()
?(
?artistsx=(artistsx:-~~(topgenres:@@1.of))
?topgenres=(topgenres,(artistsx/genre:count>=5#count:@1))
)!
? is the Dactal start operator, which is implied at the beginning of a query and thus often doesn't actually appear at all, but here we use it to effectively interleave queries that keep track of the genres we've found and the artists we have left. We begin with all the artists and no genres, and then the indented subquery does two things:
- remove the artists from the last genre, using the set disjunction filter :-~~ (which does nothing the first time, because there are no genres yet)
- find the top genre for the artists we have left and add it to the existing list of topgenres
The ! repeat operator at the end of the subquery tells it to repeat the previous operation until it produces the same result twice (meaning there's nothing left to add), which happens for me after 139 iterations:
This is a little better. Flipping back and forth, I see that j-rock was 5th in the raw version, with 62 artists, but in the iterative version it drops to 13th, because only 36 of those 62 artists aren't part of any higher-ranked genres. Similarly, symphonic power metal drops from 6th to 12th. Japanese alternative rock moves up, because only 1 of those 56 artists was being double-counted before.
Really, though, this list of 139 "representative" genres still overstates the granularity into which my listening is emotionally organized. If you do not tend to use the words "granularity" and "emotionally" in the same sentences in your internal monologue, then you should probably cut your losses and tune out now. In order to cluster genres instead of just subsetting them, we need almost every major feature of Dactal:
?artistsx=(2024 artists scored|genre=(.id.artist genres.genres),weight=(....artistpoints,sqrt))
?genre index=(artistsx/genre,of=artists:count>=5)
?clusters=()
?(
?artistsx=(artistsx:-~~(clusters:@@1.of))
?nextgenre=(artistsx/genre,of=artists:count>=10#(.artists....weight,total),count:@1)
?nextcluster=(
nextgenre.artists/genre,of=artists:count>=5
||total=(.genre.genre index.count),overlap=[=count/total]
:(.total) :overlap>=[.1] #(.artists....weight,total),count
...top genres=(.genre:@<=10),
top artists=(.artists:@<=10.name),
clustered genres=(.genre....count),
of=(.genre.genre index.artists)
:(.top genres)
)
?clusters=(clusters,nextcluster)
)!
?genre index=(artistsx/genre,of=artists:count>=5)
?clusters=()
?(
?artistsx=(artistsx:-~~(clusters:@@1.of))
?nextgenre=(artistsx/genre,of=artists:count>=10#(.artists....weight,total),count:@1)
?nextcluster=(
nextgenre.artists/genre,of=artists:count>=5
||total=(.genre.genre index.count),overlap=[=count/total]
:(.total) :overlap>=[.1] #(.artists....weight,total),count
...top genres=(.genre:@<=10),
top artists=(.artists:@<=10.name),
clustered genres=(.genre....count),
of=(.genre.genre index.artists)
:(.top genres)
)
?clusters=(clusters,nextcluster)
)!
I'm not going to claim this is "easy", but I've written variations on this algorithm in Ruby, Python, SQL and Javascript over the years, and I can tell you that all of those versions were much longer and involved way more punctuation than this, in addition to a lot more words that are about computers instead of about music.
The first two steps of the clustering are about the same as in the simpler version: eliminate any artists we've already used, and then find the top genre. Here we're scoring genres by summing up the square roots of artist points, instead of just counting artists, to measure a combination of listening breadth and listening depth, but that's added complexity in the question, not just the answer.
The clustering part is that once we have a top genre, we take all its artists and count their other genres, and then compare the overlap sizes with those genres' total artist counts (using lookups in the genre index created in the second line of the query). Other genres that overlap non-trivially with the first genre also get added to the cluster. Then the whole thing repeats. So instead of building a flat list of genres, this version builds a list of nested genre lists.
This is, for me, a lot closer to correct than the flat list, and certainly more interesting. It doesn't distribute my Japanese tastes exactly right (I don't care about anime, per se, so I usually put ReoNa and LiSA with the alt-idol groups for sonic reasons), but these first 10 statistical clusters are all aspects of my taste that I would list individually if you inadvisedly gave me an excuse, and of the 44 ways it breaks down my 2024, the only ones that get me thinking about override mechanics are towards the bottom where the genre data doesn't know that I tend to put the Spanish metal bands and the medieval rock nerds in with the other melodic metal styles.
If you want to try this on your own listening, there are now both "genres" and "genre clusters" views on the History page in Curio. But as with all of those, there is also a "see the query for this" at the bottom of the results, so if you want to experiment with variations, you can.
Although by you, as usual, I probably mean me. But by me I mean all of us.